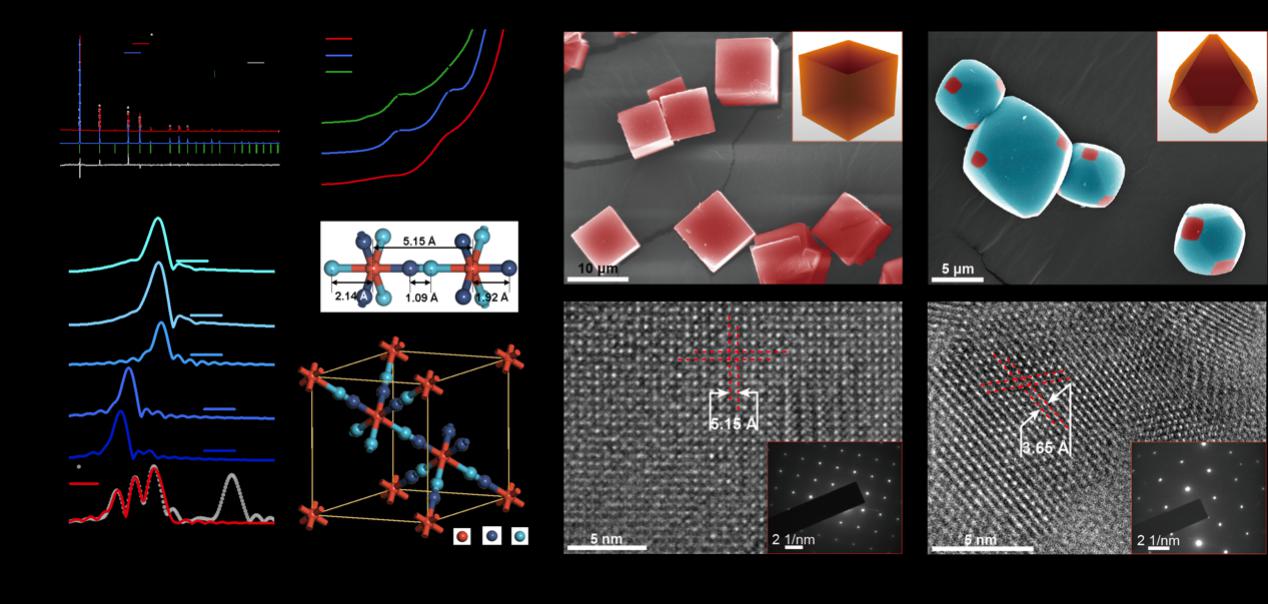
研究提出干预多模态表示学习方法







文章导读
做多模态AI的你,是否总在模型里拼命“哄”辅助模态,却发现它贡献始终拖后腿?最新的因果研究发现,这不是你不够努力,而是你一直在错误的方向上增强——真正关键的,是主模态里那些被噪声掩盖的判别性知识。中国科学院软件所提出的IMML方法,用一套违背直觉的“干预”机制,直接切断辅助模态的噪声干扰,同时精准放大主模态中的有用信号。实验验证,它能普适性地提升多种多模态模型的鲁棒性。这套因果干预逻辑怎么做?它凭什么能绕过传统增强方式的死胡同?
— 内容由好学术AI分析文章内容生成,仅供参考。
近日,中国科学院软件研究所提出一种以泛化前门准则为基础的干预多模态表示学习方法(IMML),可提升多模态模型在模态不平衡场景下的性能。
在多模态任务中,不同模态对预测结果的贡献往往不平衡,可划分为主模态和辅助模态。现有方法普遍在训练过程中增强辅助模态,以缓解模态贡献不平衡的问题。而此类方法缺乏因果解释,且判别性知识挖掘能力有限。
针对上述问题,研究团队从结构因果模型角度建模多模态表示学习,提出在考虑辅助模态,并捕捉到主模态中判别性知识与真实标签间的因果关系。基于此,团队设计了β—泛化前门校正模块,通过构造非配对模态组合、随机控制不同模态的比例贡献,削弱辅助模态中潜在的噪声干扰。
IMML包含模态判别性知识探索模块,通过构建模态判别性知识网络,为特征维度分配权重,以挖掘对任务真正有用的判别性知识。
团队进一步在多模态数据集上评估IMML的性能。实验结果表明,引入IMML后,在多个评估设置下基准多模态学习方法的性能得到提升。上述结果验证了IMML在提升多模态表征判别能力与噪声鲁棒性方面的有效性。
相关论文被IEEE Transactions on Multimedia录用。
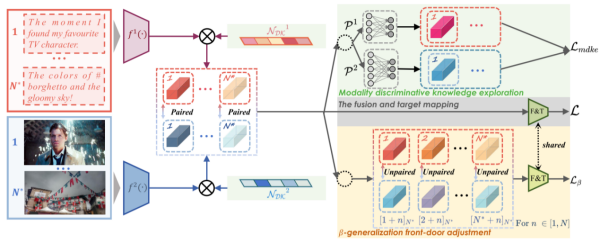
方法架构图
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章



又是论文,啥时候能开源让咱跑一下😅
搞多模态的看过来了,感觉比那些硬调权重的靠谱点
有懂行的说说这个β泛化前门校正具体咋实现的吗?