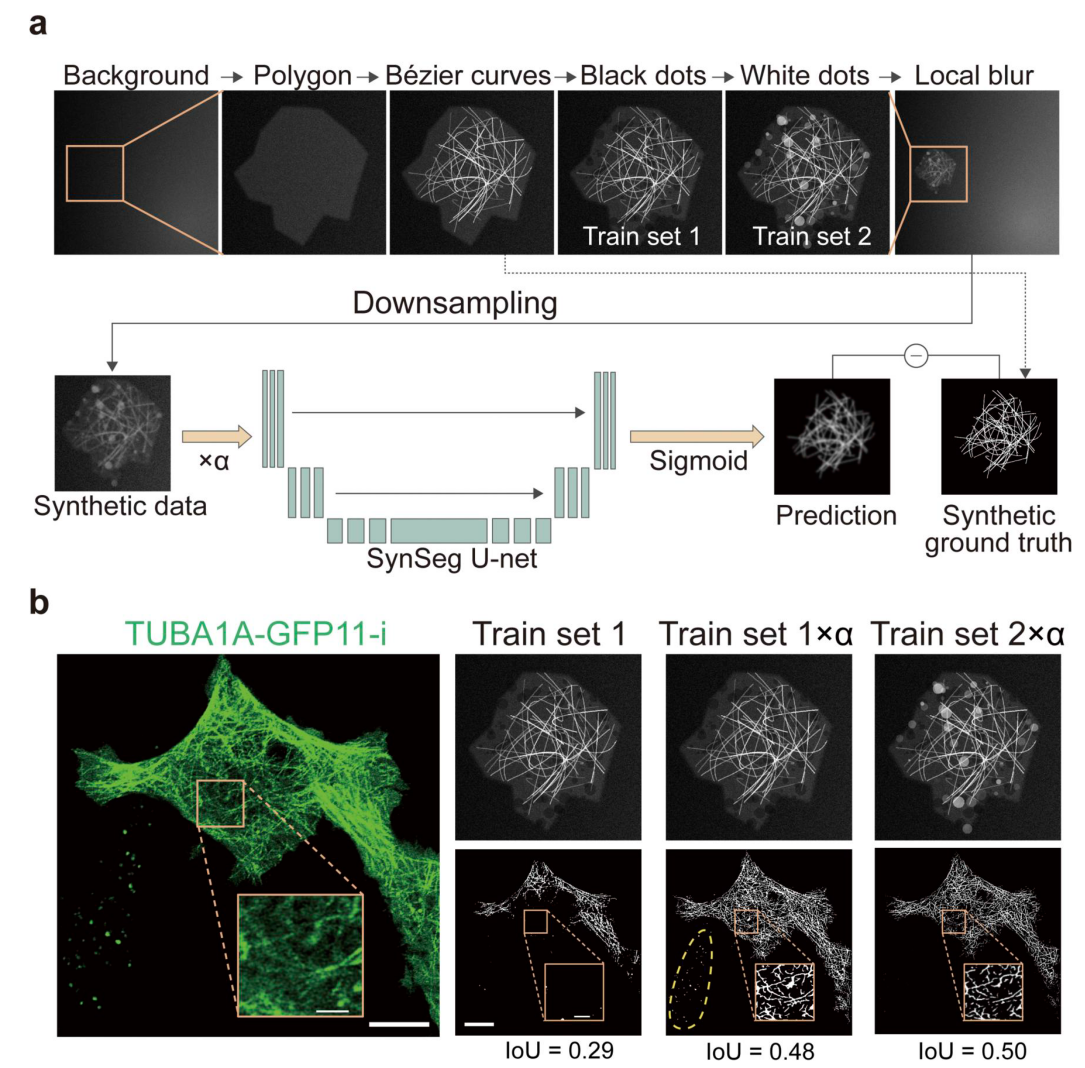







文章导读
你是否想过,破解蛋白质“暗物质”的钥匙,就藏在深海7亿条独家序列中?随着AlphaFold获诺奖,中国如何抢占AI for Science制高点?VenusPod数据集横空出世,汇聚150亿条蛋白序列,打造全球最大的蛋白质“基因宝库”。它不仅破解了小样本学习难题,更将酶研发周期从5年压缩至2个月。耐碱、耐热、可量产,30余款蛋白成功改造,10余款已落地应用。一场由AI驱动的生物制造革命,正在悄然发生。
— 内容由好学术AI分析文章内容生成,仅供参考。
一、背景
2024年诺贝尔化学奖授予AlphaFold,标志着生命科学正从“实验驱动”向“数据与计算驱动”的“科学智能(AI for Science)”范式演进。现有蛋白质和酶的数据库在深度、广度和功能标注维度上均存在不足,导致AI模型难以对海量蛋白质中的“暗物质”进行探索和优化。本案例构建了目前全球最大的蛋白质序列数据集VenusPod,包含150亿条蛋白质序列(其中7亿条序列来自我国的MEER计划,是“人无我有”核心数据壁垒)。以此数据集为基础,打造了世界领先的AI驱动的酶发现与设计引擎,解决“找不到、不好用”的工业用酶瓶颈问题,直接服务于生物医药、绿色制造等国家战略领域。
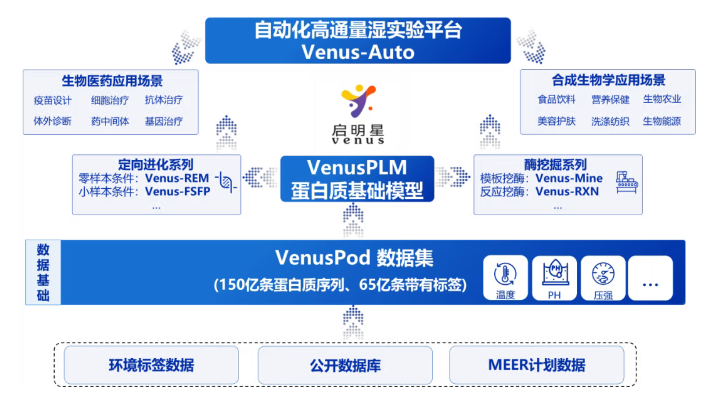
图:VenusPod数据集及Venus系列模型建设方案
二、方案和成效
一是汇聚多维蛋白质信息,突破训练数据多样性瓶颈。VenusPod整合多个数据库,涵盖150亿条蛋白质序列,其中65亿条具备功能标签。这其中包括7亿条深海序列,源自我国MEER计划,是我国独有的珍贵资源。
二是突破蛋白质设计中小样本学习的难题。基于预训练与小样本微调范式,Venus系列模型可从海量序列中筛选具有特定功能的蛋白质,并预测高性能突变体,将传统方法2~5年的研发周期缩短到2~6个月,显著降低实验时间与成本。
三是建立AI预测与实验验证高效协同的闭环体系。Venus模型结合自动化实验平台,构建“干实验预测—湿实验验证—数据回流”的迭代流程,实现AI高通量预测与实验验证的协同,持续推动模型性能优化。该平台过去1年半成功改造30余款蛋白,其中10余款落地产业化,包括耐碱VHH蛋白、极度耐碱亲和填料(ProteinA)、极度耐热DNA聚合酶(Phi29)等。
三、创新点
一是汇聚多维蛋白质信息,突破训练数据多样性瓶颈。VenusPod整合多个数据库,涵盖150亿条蛋白质序列,其中65亿条具备功能标签。这其中包括7亿条深海蛋白序列,源自我国MEER计划,是独有的珍贵资源。
二是突破蛋白质设计中小样本学习的难题。基于预训练与小样本微调范式,Venus系列模型可从海量序列中筛选具有特定功能的蛋白质,并预测高性能突变体,显著缩短研发周期,降低实验成本。
三是建立AI预测与实验验证高效协同的闭环体系。Venus模型结合自动化实验平台,构建“干实验预测—湿实验验证—数据回流”的迭代流程,实现AI高通量预测与实验验证的协同,持续推动模型性能优化。
作者: INS 供稿单位: 自然科学研究院
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章




暂无评论...