生态站点观察数据挖掘取得新突破 ——中国森林凋落物分解速率空间模拟与气候变化响应研究新进展







文章导读
做森林碳汇评估时,你是否还在依赖离散站点数据,苦于无法获得高精度空间分布?中国264个站点的实测数据与AI模型结合,首次实现了1km分辨率凋落物分解速率的全国模拟。数据揭示了一个反直觉的事实:气候变化下,华北阔叶林分解加快22.5%,而西北阔叶林反而减慢10.8%——同一个国家,命运截然相反。决定这一差异的,并非温度本身,而是一个被传统模型长期忽略的交互因子。如果你还在用旧方法估算碳储量,这份结果可能会让你彻底重算。
— 内容由好学术AI分析文章内容生成,仅供参考。
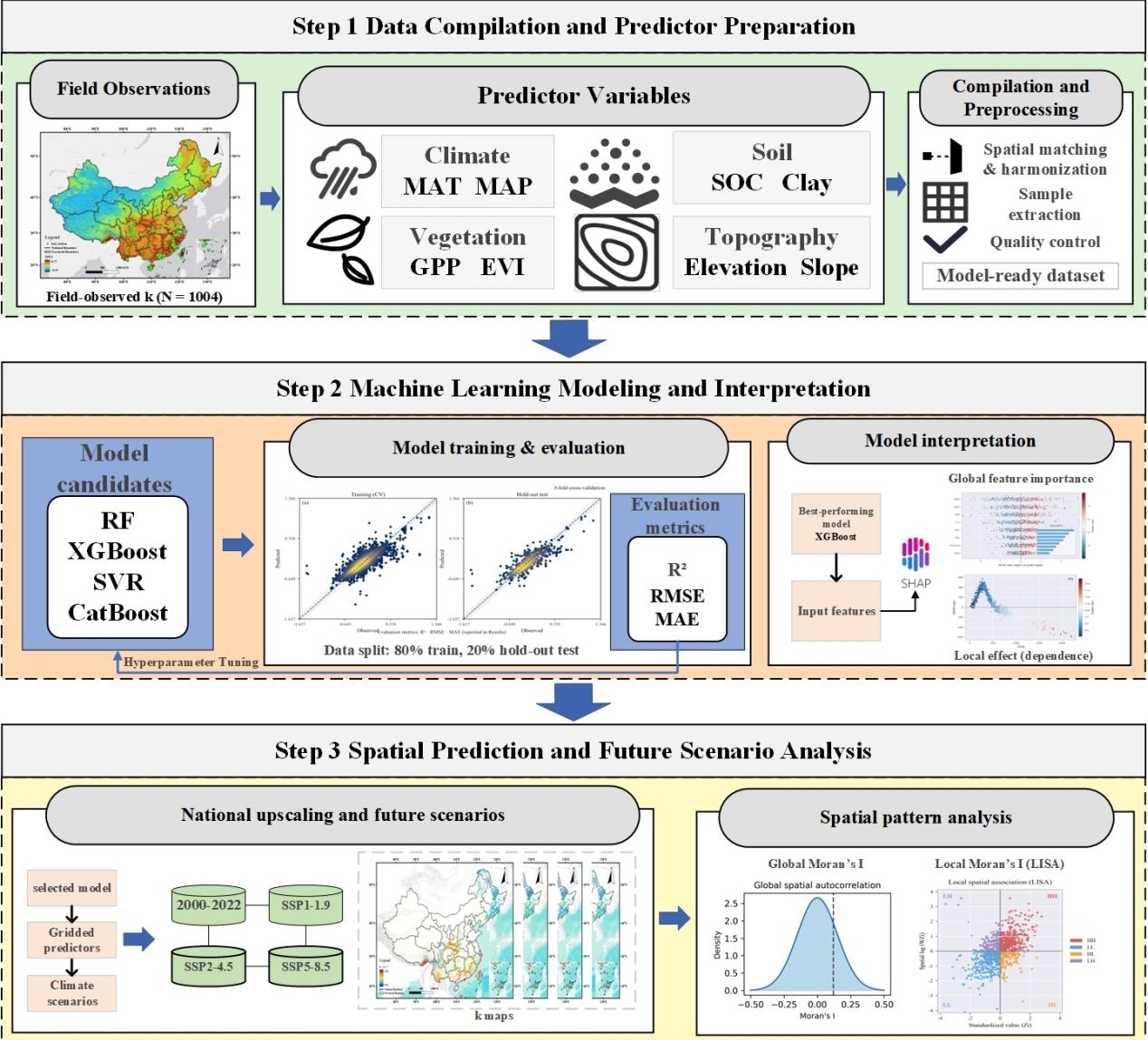
图1 研究方法总体框架图
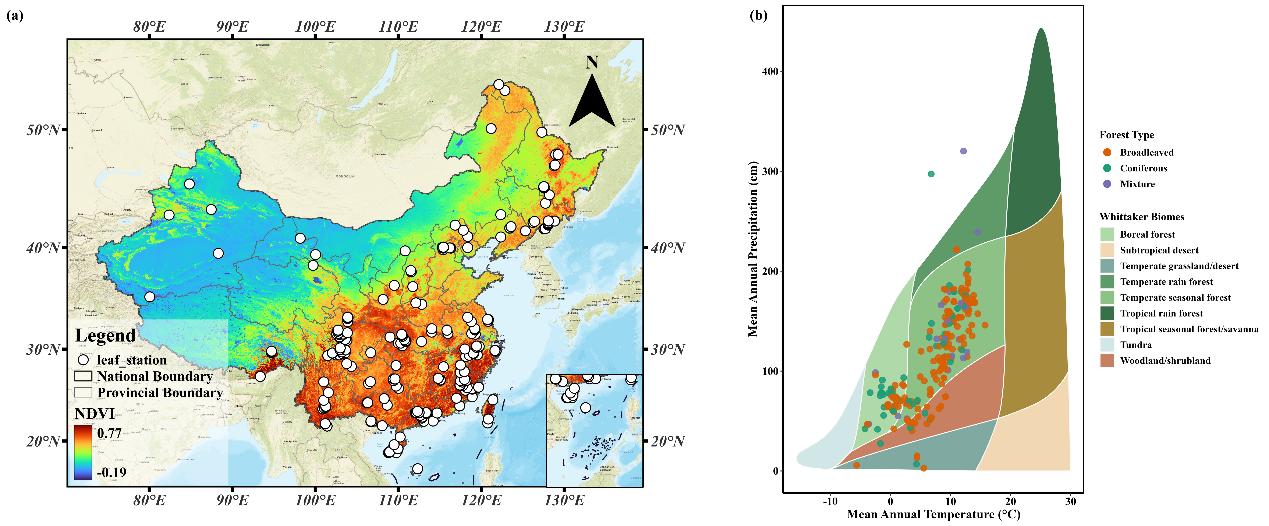
图2 中国森林凋落物分解观测数据站点空间分布
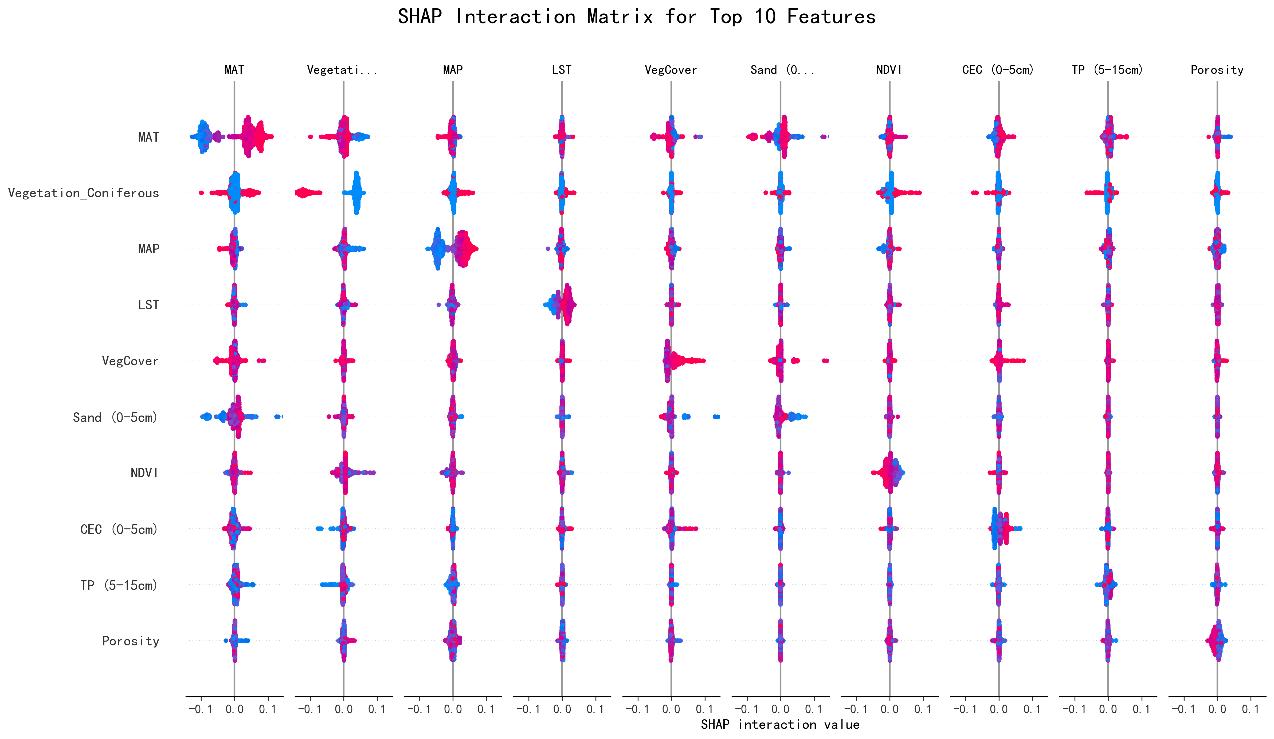
图3 凋落物分解关键驱动因子及交互作用特征
森林凋落物分解是连接植被碳输入与土壤碳库的关键生态过程,对森林生态系统中碳循环与养分循环具有核心调控作用。一直以来,全国尺度上缺乏高分辨率、空间连续的凋落物分解速率数据,制约了对森林碳储量动态及其空间异质性的系统认知。针对这一问题,资源所智慧林草创新团队构建了多源数据驱动的智能建模框架,实现了中国森林凋落物分解速率的高精度空间模拟,并系统解析了其主导驱动因子,突破了大尺度定量研究的技术瓶颈。
智慧林草创新团队前期在森林碳循环关键过程中已取得突破性进展:“一种多模态数据融合的森林凋落物智能预测方法”(Chen S H, Zhang H Q, Yang J,et al.Ecological Indicators,2026,182:114497),以及“基于人工智能的中国1km分辨率凋落物量逐月预测新方法”(Guo, M L, Zhang, H Q, Tan, J W,et al.Journal of Forestry Research,2026,37:24)。本研究基于以上成果进一步深化研究,系统整合了全国264个森林生态系统站点的观测数据,构建了涵盖气候、植被、土壤和地形四大类多源环境变量的统一数据体系,所有变量均统一至1km空间分辨率,并完成多源数据的尺度聚合,确保时空一致性。
为精准捕捉非线性驱动关系,系统比较了随机森林(Random Forest)、XGBoost、CatBoost和支持向量回归(SVR)四种主流机器学习模型,经交叉验证与独立测试集评估,XGBoost模型的预测精度和稳定性最优,因此选定其作为空间模拟与机制解析的模型。在建模过程中,采用随机搜索结合5折交叉验证进行超参数优化,有效避免过拟合,并将SHAP(Shapley Additive Explanations)方法引入森林凋落物分解研究,揭示了中国森林凋落物分解速率的主要驱动因子。
验证结果表明,模型在独立数据集上决定系数R²约为0.68,说明具备在全国范围应用的可靠性。通过SHAP分析,研究发现影响分解速率的关键因素:年均温是主导因子,地表温度和年降水量也发挥重要作用,而针叶林会明显减缓分解速度。这些因素共同塑造了我国分解速率“东南高、西北低”的格局:华南、西南温暖湿润的林区分解最快,东北寒温带针叶林和西北干旱区则相对缓慢,全国平均分解速率约为每年0.85次。在SSP5-8.5高排放情景模拟中,华北温带阔叶林分解速率将提升22.5%,而西北阔叶林和东北针叶林分别下降10.8%和3.5%,这体现了温度、水分与植被类型的复杂交互作用。
该成果实现了从生态系统站点“点状离散观测”到“空间连续预测”的跨越,同时通过可解释AI技术,让模型不再是“黑箱”,而是成为揭示森林碳循环内在机制的科学工具,为碳汇评估、生态修复以及碳中和路径规划提供科学依据。
研究论文“Mapping the controls and climate-induced vulnerability of forest litter decomposition in China”发表在《Ecological Informatics》(新锐分区1区TOP,IF=7.3),资源所人工智能与可视化实验室硕士研究生雷豪为第一作者,张怀清研究员为通讯作者。该项研究得到国家重点研发计划项目(2023YFF1303701)的资助。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章


华北分解速率涨22.5%这个数有点吓人,碳汇估算是不是也得跟着重算一遍?
SHAP放在这个场景里还挺合适,至少能看出温度水分谁在拉扯。
264个站点听着不少,但西北那边点位够密吗?
R²才0.68,拿来做全国预测我有点虚。