科研人员开源本地通用幻灯片智能体模型与环境系统







文章导读
你手头有一堆PPT要做:专家要求数据严谨、图片要真实呈现、排版还得一键适配不同屏幕——但现有AI生成的幻灯片常常“看起来合理却漏洞百出”。大多数人还在把希望寄托给更大的模型或昂贵的云算力,忽略了两个关键痛点:生成内容的可验证性和渲染后的视觉自检。中国科学院的软件团队把这两点一口气解决了:把幻灯片模型和能“现场跑代码、截图、再修正”的沙箱环境一起开源,并在低成本显卡上可复现。听起来像是效率翻倍、省掉外包的一招,但真正值得你关心的,是他们如何用独立评审与视觉闭环把“看得见的错误”变成可迭代的优化——这背后藏着一个决定你到底要不要放弃现有工作流程的衡量标准,你敢不看看这套系统到底能替你省下多少时间和风险吗?
— 内容由好学术AI分析文章内容生成,仅供参考。
近日,中国科学院软件研究所团队开源第二代幻灯片智能体系统DeepPresenter,实现了将幻灯片智能体模型与完整的智能体沙箱环境一同开源,可在单张消费级显卡和终端上一键部署,并适配国产化算力生态。该成果重构了AI制作幻灯片逻辑,使智能体不仅能“深度探索”,还能“亲眼所见”。
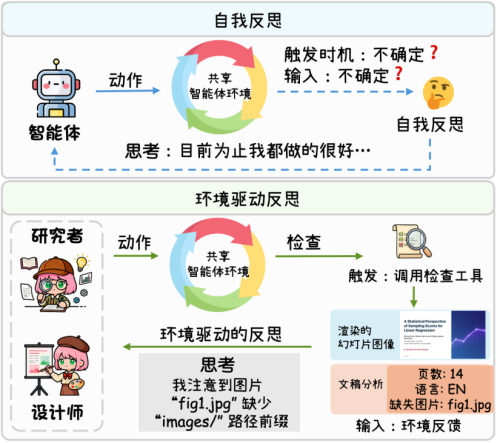
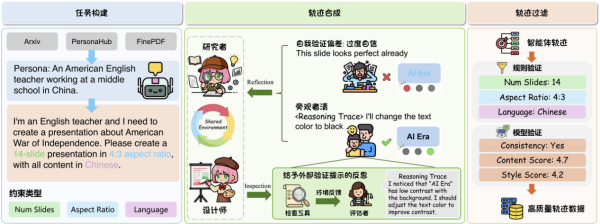
在内容生成方面,团队构建了包含20余种专业工具的共享智能体环境,集成了基于Docker的智能体沙箱、arXiv实时文献检索,以及Python代码执行与数据可视化等能力,为幻灯片内容的专业性与数据准确性提供保障。在排版优化方面,团队提出了环境感知反思机制。这一机制通过“生成—渲染—审视—修正”的视觉闭环工作流,使智能体在每页幻灯片生成后,调用沙箱内浏览器将代码渲染为真实图片,并基于截图进行自适应检查与迭代优化,直至排版效果达到预期标准。在模型训练方面,团队设计了系统化的训练流水线。该训练流水线基于PersonaHub与arXiv等多源数据集构建高多样性任务数据,并在指令中定义页数限制、宽高比及语言等细粒度约束条件;引入独立评审机制以克服智能体的自我验证偏差,由独立模型作为外部评估者指出生成产物中的排版或逻辑缺陷;在1152个任务中筛选出802条高质量智能体轨迹用于监督微调训练,涵盖中英双语、多种宽高比及复杂指令约束场景。
为验证有效性,团队在预留的128个测试任务中使用PPTEval进行系统评测,并与多种主流幻灯片生成方案进行对比。结果显示,DeepPresenter(pptagent 2.0)9B版本获得4.19综合评分,与闭源模型GPT-5(4.22)表现接近,优于其他幻灯片生成方案。成本—性能分析表明,DeepPresenter-9B处于前沿曲线的最优平衡点位置,能以低于闭源模型的算力成本实现同等级别的生成质量。所有生成内容均输出为可编辑的pptx格式,支持用户自由修改与二次创作。

© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章




说白了不就是自动套模板?哪来的“亲眼所见”🤔
9B模型干翻GPT-5?我不信,除非让我试试😂
排版能自己改就行,最烦生成完不能动的ppt
又是Docker又是arXiv的,新手根本不敢碰啊
之前搞过类似项目,光渲染闭环就折腾了俩月😭
国产算力适配听着挺香,但实际用起来别又卡脖子
这玩意真能在3060上跑?求问显存占多少