
图神经网络框架研究取得进展







文章导读
当你在处理亿级边规模的图神经网络时,是否总卡在GPU间通信瓶颈上?多数人还在用传统框架硬扛数据洪流,结果80%时间浪费在无效传输上。我们发现,中科院最新推出的TAC框架,靠一个被忽视的“数据亲和缓存”设计,让端到端训练速度实现倍级提升。它不只改变了缓存策略,更重构了CPU与GPU之间的数据交接方式——实测中,稀疏矩阵计算竟充分利用了Tensor Core的闲置算力。这项突破已登上ACM SIGPLAN顶会,但真正令人震惊的,是它如何用软件优化绕过硬件限制。如果你正被大规模GNN训练拖慢节奏,这个细节可能决定你是继续烧钱加卡,还是直接换条技术路径。
— 内容由好学术AI分析文章内容生成,仅供参考。
图神经网络(GNNs)在生物医药、知识图谱和AI4S等领域具备应用潜力。随着真实应用场景中图规模扩展至亿级边及以上,GNN训练面临通信开销与计算等问题。
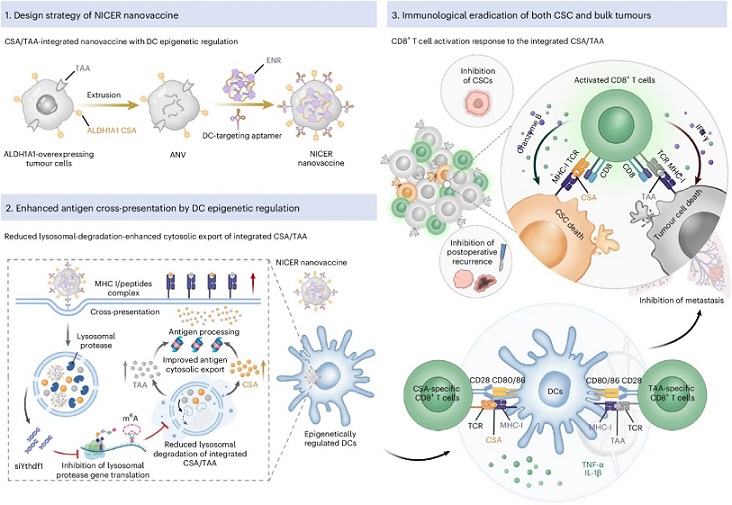
近日,中国科学院计算机网络信息中心研发了TAC框架,融合数据亲和缓存填充算法、稀疏性感知的混合矩阵存储格式、多层次细粒度训练流水线三大技术,可提升缓存局部性有效降低全局通信开销,并借助Tensor Core实现稀疏矩阵计算加速。实验证明,该框架端到端性能优于其他框架。
相关研究成果已被第31届ACM SIGPLAN编程语言与并行实践原理年会录用。研究工作得到国家重点研发计划、中国科学院相关项目的支持。

TAC 框架系统架构图
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。







相关文章




这个框架有文档吗?求个链接
能用在知识图谱上吗?
Tensor Core能加速多少?有具体数据吗?
之前搞过GNN训练,通信开销确实头疼
看着挺复杂的,完全看不懂😵
要是开源就好了,想跑跑看
这个TAC框架有人试过吗?