






文章导读
当AI能完美伪造你的脸和声音,我们还能相信眼睛和耳朵吗?西安交大孙鹤立教授团队最新突破,提出全新二阶段学习范式,打造迄今最大的自监督视听人脸表征数据集,融合音频与画面细节,精准捕捉微小伪造痕迹。其研发的HOLA模型在80万样本测试中力压全球对手,夺得ACM Multimedia 2025 1M-Deepfake挑战赛冠军,性能领先第二名近5个百分点。这项技术不仅为对抗深度伪造提供利器,更将推动数字内容安全体系的重构。
— 内容由好学术AI分析文章内容生成,仅供参考。
随着Deepseek-R1、GPT-5以及通义万相等大模型的接连出圈,人工智能生成内容(AIGC)技术受到越来越多的关注。AIGC在为内容创作、文化传播带来新发展契机的同时,也为虚假信息、合成媒体滥用以及深度伪造等新型社会安全威胁的滋生与扩散提供了技术基础和发展温床。为此,针对AI生成式信息的检测,亟需发展具备跨模态感知与细粒度辨伪能力的技术手段,以应对日益复杂的多重伪造挑战。
在国家自然科学基金等项目资助下,西安交通大学电信学部计算机学院孙鹤立教授团队针对视听跨模态场景下的伪造人脸检测开展研究,提出通用面部表征建模与强判别性伪造特征捕捉的二阶段学习范式(如图1)。具体而言,首先构建出当前业界最大的多源混合式自监督视听人脸表征学习数据集以支撑大规模编码器预训练,其次设计提出迭代感知的渐进式分级上下文聚合组件以促进高效跨模态融合与伪造线索捕获,最后引入伪监督信号语义注入策略以从全局层面进一步拓宽深度模型的判别边界,并提升对于细微人脸伪造痕迹的鲁棒检测能力。在多媒体领域国际顶级会议ACM Multimedia 2025(计算机学会推荐的A类会议)上,所提出的方法超越了来自美国普渡大学、韩国成均馆大学、中国科学技术大学以及Pindrop(美国语音安全领域头部公司)等多个国内外研究团队,获得2025年1M-Deepfake检测全球挑战赛总冠军。在共包含80万条样本的测试集上,取得超出第二名4.76个百分点的优异成绩。
该研究工作为AI生成式信息检测技术的发展提供了一种新方案,并能够为通用视听场景理解以及数字内容安全治理体系的构建带来可行的实践参考。
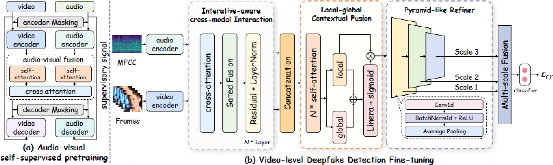
图1. 面向伪造人脸检测的二阶段学习范式示意图
同时,基于上述研究成果形成的学术论文HOLA: Enhancing Audio-visual Deepfake Detection via Hierarchical Contextual Aggregations and Efficient Pre-training已被ACM Multimedia 2025国际多媒体大会接收。孙鹤立教授与计算机学院2023级硕士研究生武雪程为共同第一作者,西安交通大学为第一署名单位。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章




期待这项技术能帮助我们识别更多AI生成的内容
作为西交校友,看到母校在AI领域取得突破很骄傲!
想了解下这个二阶段学习范式的具体实现细节🤔
4.76个百分点的差距,在80万样本上已经很显著了
团队实力很强啊,能超越这么多国际知名院校和公司
希望能尽快应用到实际场景中,现在网上假视频太多了
这个研究方向真的很重要,现在的AI造假越来越难分辨了👍