北京师范大学人工智能学院教授余先川团队研究成果入选国际多媒体会议Outstanding Paper







文章导读
在全球顶级学术会议ACM MM上,北京师大余先川团队的研究成果从5330篇投稿中脱颖而出,以仅1/800的杰出率入选。他们究竟解决了什么难题?传统多视图聚类中致命的“假阴性问题”长期困扰学界,导致性能骤降。团队独创的PAUSE框架,通过伪标签引导与普适学习技术,巧妙规避了这一瓶颈,在多个数据集上碾压11种前沿方法。这项突破性进展如何重塑人工智能聚类算法的未来?答案就在这篇杰作之中。
— 内容由好学术AI分析文章内容生成,仅供参考。
国际多媒体会议(ACM International Conference on Multimedia,简称ACM MM)由国际计算机协会(ACM)发起,是多媒体处理、分析与计算领域最具影响力的国际会议。该会议被推荐为中国计算机学会CCF-A类会议。ACM MM 2025于2025年10月27日至31日在爱尔兰都柏林召开。本次会议共收到5330篇投稿,接受1250篇,接受率23.45%,其中的Content Theme收到2400余篇,仅有3篇获Outstanding Paper(杰出论文),杰出率约1/800,人工智能学院教授余先川团队的研究成果入选。
近年来,对比学习因能够强化跨视图一致性并利用多源互补信息提升异构数据分析能力,已成为多视图聚类(MVC)研究的重要方向。然而,传统的对比MVC方法存在一个固有的局限性:它们的一对多对比机制会导致假阴性问题(FNP),即语义上相似的类内实例被错误地排斥。这种现象损害了类内一致性,并最终降低了聚类性能。
针对上述问题,余先川课题组提出了一种新颖的伪标签引导的普适学习(PAUSE)框架,用于稳健的多视图聚类。PAUSE在两个协同阶段运行:一个预热阶段,采用双重对比学习来生成可靠的伪标签,从而建立稳健的语义关系;一个微调阶段,通过在锚点实例和类外质心之间进行Mixup来合成普适样本,并由获得的伪标签引导。这种独特的机制构建了广义的负类,扩大了类间间隔,同时保持了类内凝聚力。至关重要的是,扩大的决策边界可以防止错位类内实例的错误分类,从而有效避免了FNP,而无需显式的负对校正。本项研究进一步设计了一种稳健的普适对比损失,通过自适应边界约束显式地强调跨视图一致性。
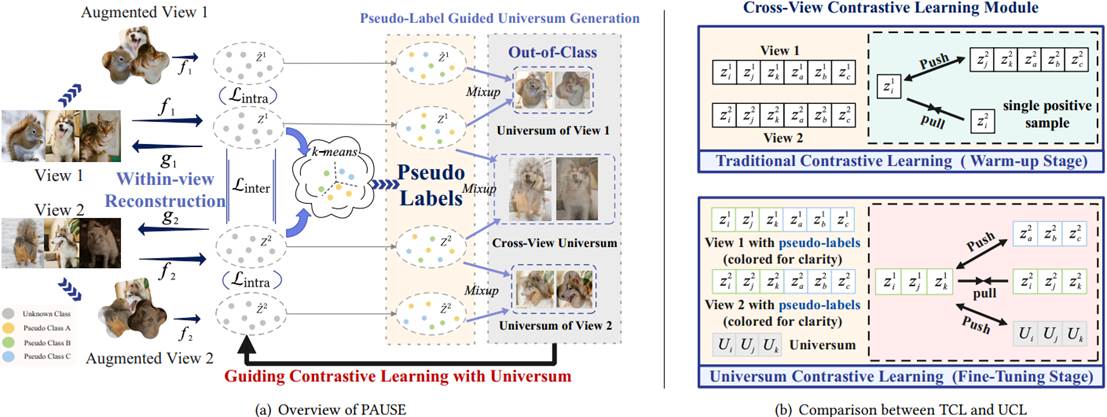
PAUSE框架概述
该项研究提出了一种名为 PAUSE 的稳健对比多视图聚类框架,用于缓解传统对比学习中假负对(FNP)问题。PAUSE 结合伪标签引导的普适学习与 Mixup 技术,生成具备泛化能力的负样本,以扩大类别边界、降低误分类风险,并提升类内紧凑性和类间可分性。该框架通过两阶段训练实现:预热阶段利用双重对比学习生成反映跨视图语义关系的伪标签,微调阶段则在伪标签指导下将锚点样本与类外中心混合,生成分布在中性边界区域的普适样本,从而主动预防假负对的产生。实验结果表明,PAUSE 在五个多视图数据集上均显著优于11种先进方法,并在复杂的跨模态数据上表现出较高的稳健性。
该研究以“Robust Multi-view Clustering via Pseudo Label Guided Universum Learning”为题入选国际会议ACM MM 2025 Outstanding Paper。北京师范大学为论文唯一完成单位,人工智能学院2024级博士生汪真西为论文第一作者,余先川为通讯作者,论文作者还包括人工智能学院2022级博士生殷宗耀和2024级博士生侯宇杰。该研究得到了国家自然科学基金(42172323、42472360)资助和北京市自然科学基金-丰台创新联合基金(L25044)资助。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。







相关文章



看到“唯一完成单位”就安心了,国产科研越来越硬气了
又是对比学习的老问题,总算有人从根上想办法了,支持!
1/800的杰出率…这不得赶紧催更后续研究?坐等开源代码!😊
伪标签+Mixup的思路挺新颖,不过实际部署会不会很耗资源啊?
Outstanding Paper才3篇?这成果也太顶了吧,吃瓜群众表示佩服
这PAUSE框架听起来真能解决FNP问题,比之前方法聪明多了
北师大AI团队太强了!ACM MM杰出论文含金量拉满👍