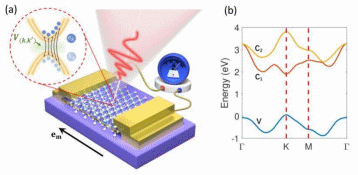







文章导读
华中科技大学陶文兵教授团队在ICCV 2025上发表最新成果“DISC”,提出3D语义场景补全的新范式,通过解耦实例与场景上下文信息,显著提升自动驾驶环境感知的精度与效率。团队采用双流架构,在BEV空间中以DQG和DACD模块分别处理实例与场景类别问题,有效改善结构不连贯与语义模糊等挑战。实验结果显示,DISC在SemanticKITTI和SSCBench-KITTI-360数据集上均达SOTA水平,单帧输入性能超多帧方法。
— 内容由好学术AI分析文章内容生成,仅供参考。
近日,计算机视觉领域国际会议ICCV 2025(International Conference on Computer Vision)接收我校陶文兵教授团队关于3D语义场景补全的最新研究成果”Disentangling Instance and Scene Contexts for 3D Semantic Scene Completion”。该研究提出了一种全新的双流范式DISC(Disentangling Instance and Scene Contexts),通过解耦实例与场景上下文信息,显著提升了自动驾驶环境感知的精度与效率,为实现更安全的自动驾驶系统提供了关键技术支撑。我校陶文兵教授为论文的通讯作者,人工智能与自动化学院硕士研究生刘恩瑀、博士生于恩为论文共同第一作者,博士生陈思佳等人参与了本工作。
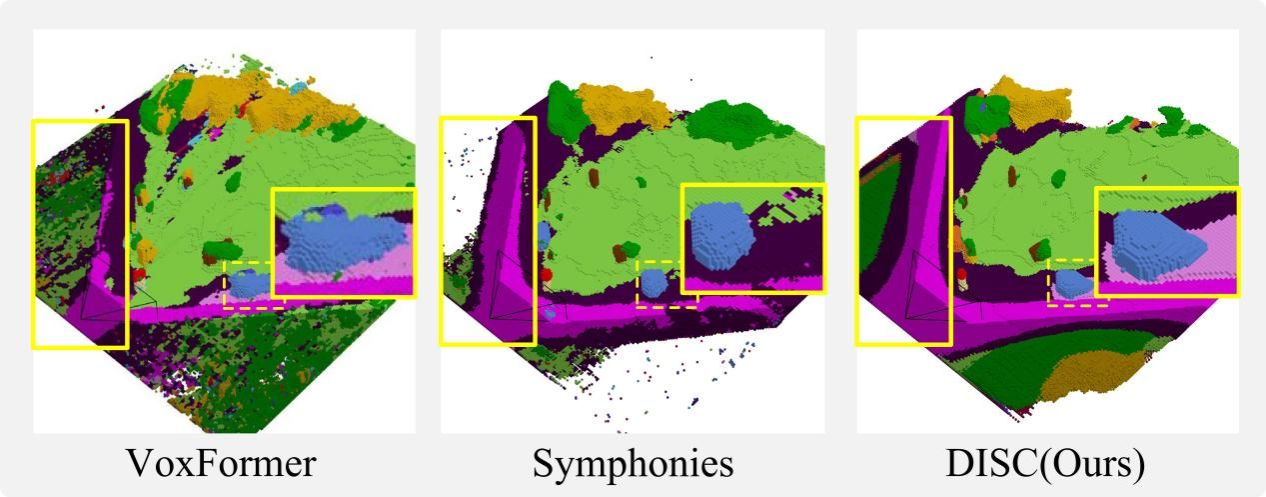
图1:不同方法的补全效果对比。融入实例与场景特定信息显著提升了对应类别的预测精度
3D语义场景补全(SSC)作为自动驾驶环境感知的核心任务,旨在从稀疏传感器输入中联合预测场景的完整几何结构与语义信息,为导航决策和障碍物规避提供全面环境认知。近年来,基于视觉的SSC方法因成本优势逐渐成为研究主流,然而传统体素(voxel)方法将体素作为特征交互基本单元,存在类别级信息利用不足的固有局限,导致实例类别易出现遮挡丢失、语义模糊,场景类别则面临结构不连贯等问题。
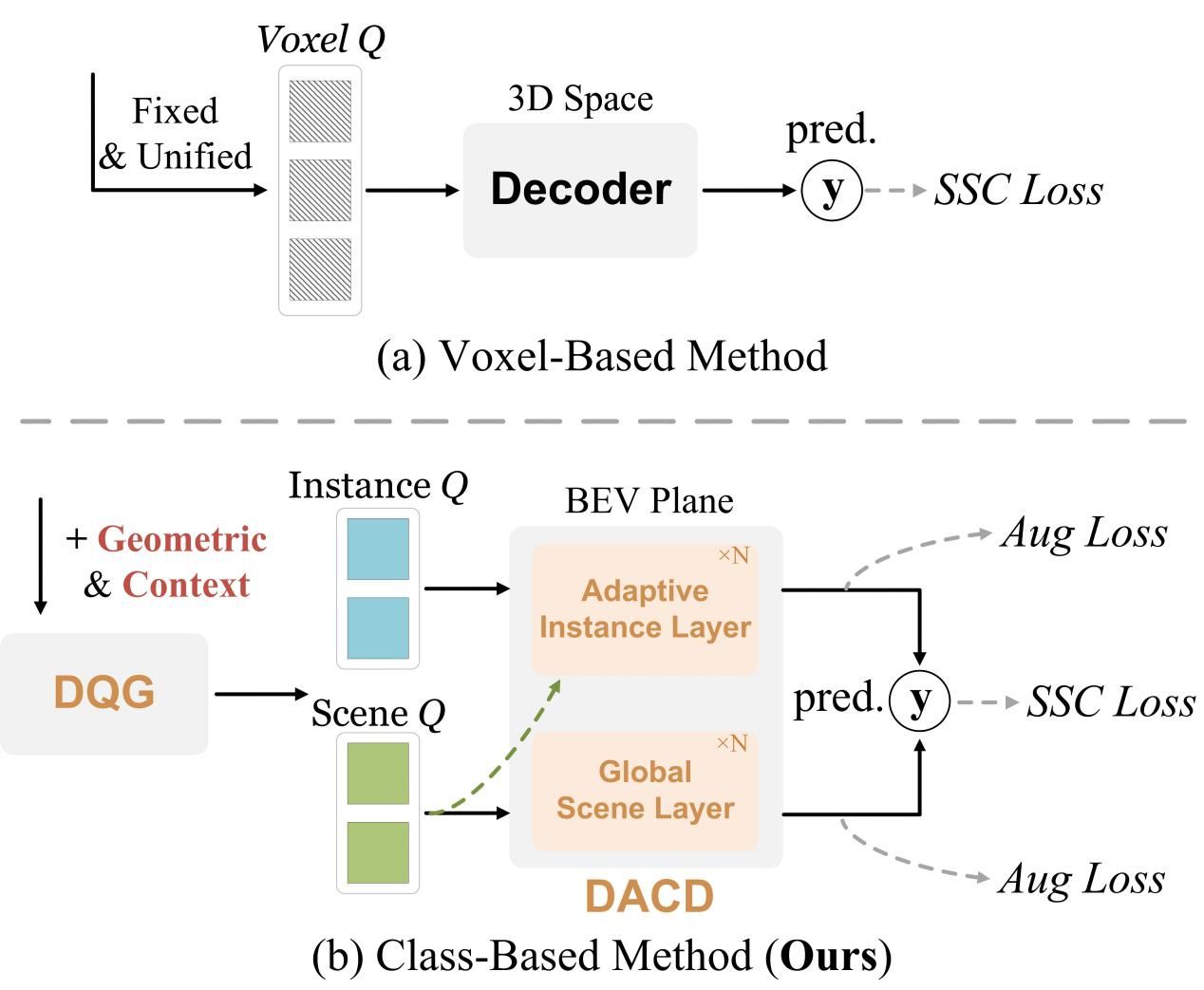
图2:主要架构对比。DISC的类别基方法与传统体素基方法的关键差异(红棕色高亮)在于:使用语义和几何先验初始化查询,采用双流结构和定制模块实现类别判别式补全
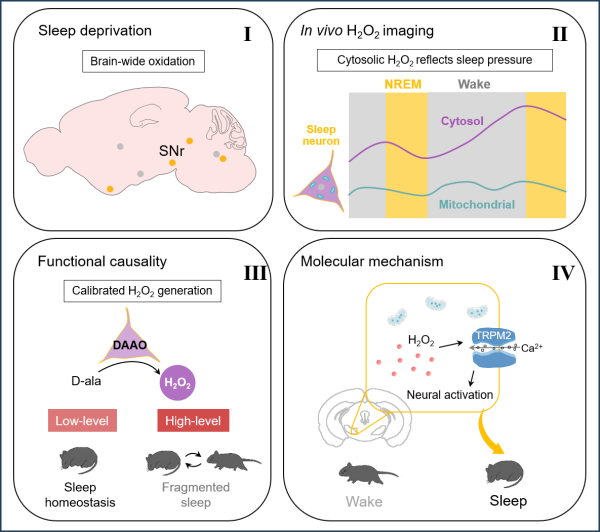
针对这些挑战,研究团队创新性地提出了类别感知的双流架构DISC,彻底摆脱传统体素基范式束缚,在BEV(鸟瞰图)空间中实现实例与场景上下文的解耦优化。该架构通过两个核心模块充分释放类别级信息价值:判别式查询生成器(DQG)和双注意力类别解码器(DACD),从根本上解决了传统方法面临的三大瓶颈:首先是结构信息保留,用独立的实例与场景查询替代体素查询,整合类别专属几何与语义先验;其次是针对性优化,为实例与场景类别设计专用解码模块,分别解决其独特挑战;最后是计算效率提升,通过上下文解耦缓解BEV空间高度轴建模限制,降低计算成本。
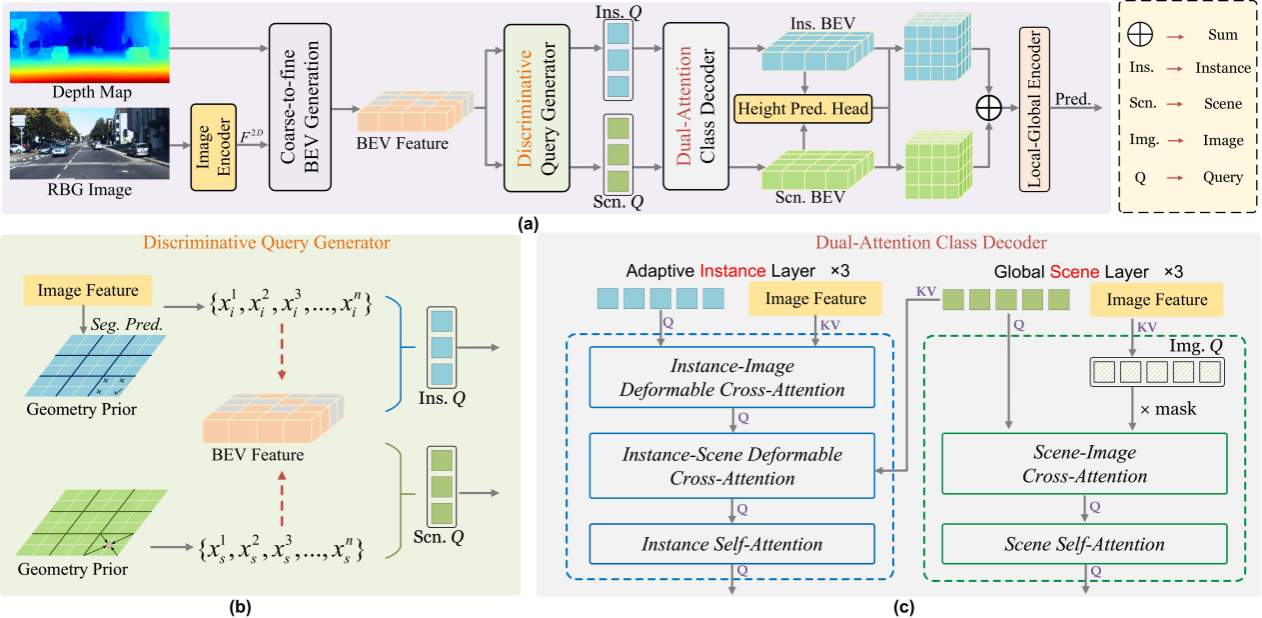
图3:DISC主要架构。DISC以单目图像作为输入,使用DQG模块和DACD模块针对性处理实例类别和场景类别的差异化问题。
DQG模块首先基于实例与场景类别的固有属性,在BEV(鸟瞰图)平面为二者分别初始化独立的查询向量。这些查询向量将在后续解码过程中提供丰富的语义信息,从而显著提升特征交互的针对性和效率。研究团队特别指出,相较于3D空间,BEV空间能显著降低模型的显存消耗。然而,传统方法在BEV空间中的一个主要缺陷是高度轴信息的模糊性。例如,在同一BEV网格内,近地面的道路与行人存在显著的高度差异,这会导致3D重建时出现垂直方向上的特征混淆问题。为解决此问题,DISC采用上下文解耦策略,让具有不同高度分布特性的类别在各自独立的处理流中进行学习,从而有效缓解了上述矛盾。
此外,DACD解码器针对实例与场景类别错误的不同根源,设计了两种专业化处理层:1)自适应实例层(AIL):专注于解决实例类别面临的投影误差与遮挡问题。该层通过动态融合图像特征与场景上下文信息,并利用注意力机制定位及恢复被遮挡的实例细节。例如,当车辆部分被建筑物遮挡时,AIL能够结合场景上下文(如车辆所在的停车位区域)和图像特征(如可见的车轮轮廓),推断出完整的车辆形态。2)全局场景层(GSL):旨在增强场景类别的全局推理能力,通过建立跨区域特征交互实现。实验结果表明,GSL能有效解决诸如将道路误判为地形等拓扑错误。其核心在于利用注意力机制捕捉远距离场景元素间的关联性,从而确保道路网络预测的连续性与完整性。
研究团队在 SemanticKITTI 和 SSCBench-KITTI-360 两个权威基准数据集上对 DISC 进行了全面评估。实验结果表明,DISC 在两项基准上均取得了最先进(SOTA)性能。尤为突出的是,仅使用单帧图像输入的 DISC 首次超越了依赖多帧输入的现有 SOTA 方法。具体而言,在实例类别的 mIoU(平均交并比)指标上,DISC 相较现有的单帧 SOTA 方法提升了 17.9%,相较多帧 SOTA 方法也提升了 11.7%。为更直观地验证模型效果,研究团队进行了大量的可视化实验。结果显示,DISC 在复杂城市场景中展现出卓越的补全能力:例如,能准确恢复被遮挡行人的完整形态;对于长距离道路,可有效维持其拓扑结构的连续性。这些可视化结果进一步验证了 DISC 方法在 3D 语义场景补全领域的领先性能。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章




暂无评论...