






文章导读
你以为大语言模型真的"懂"文化差异?当ChatGPT面对亚洲家庭伦理和西方个人主义冲突时,它默认站哪边你可能从未察觉。北京大学信息管理系的一项最新研究揭开了这个被忽视的盲区:现有AI不是在学习多元文化,而是在用西方价值观"覆盖"全球。研究团队提出的OG-MAR框架,首次让模型能够调用真实社会调查数据做推理——但最关键的问题是,这套方法能否打破硅谷主导的技术霸权,让非英语国家的文化真正被"理解"而非被"标注"?三篇顶会论文背后,藏着AI本土化的真正突破口。
— 内容由好学术AI分析文章内容生成,仅供参考。
近日,由信息管理系2019级大数据管理与应用专业系友徐源德(现在韩国人工智能企业Enhans.ai担任研究员),元培学院2020级大数据管理与应用方向本科生崔元皙、2020级大数据管理与应用专业本科生高晙瑞、2020级信息管理与信息系统专业李周炫,信息管理系周庆山教授和步一助理教授等合作的研究论文“Toward Culturally Aligned LLMs through Ontology-Guided Multi-Agent Reasoning”被国际机器学习大会(International Conference on Machine Learning,ICML)录用。值得一提的是,徐源德、崔元皙、高晙瑞、李周炫均为北京大学韩国留学生,他们的积极参与不仅展现了国际化学术合作的良好成效,也体现了信息管理系在留学生培养与有组织科研方面的融合成果。
当今,大语言模型正越来越多地被应用于需要理解不同文化背景的决策场景。然而,由于训练数据在地区和语言上的分布并不均衡,且模型缺乏对人类价值观之间关系的结构化理解,它们往往更容易默认西方主流文化立场,在涉及社会规范、道德判断和价值选择的问题上产生系统性偏差。尽管现有方法能够在一定程度上引导模型生成更符合特定文化语境的回答,但这些方法通常缺乏真实人口与社会调查数据的支撑,也常将价值观视为彼此孤立的信号,因而在一致性和可解释性方面仍存在不足。针对上述问题,该文提出了本体引导的多智能体推理框架(OG-MAR)。与仅依靠提示词或简单角色设定来调整模型回答的方法不同,OG-MAR的核心思路是先把真实社会调查中的文化价值信息整理成一个可检索、可解释的知识基础,再让模型在推理时调用这一基础,从而减少对模糊文化标签或西方默认价值观的依赖。研究在6个区域性社会调查基准上对OG-MAR进行了系统评估,结果显示,OG-MAR在4款模型上均超过零样本推理、角色分配、自洽、辩论和其他基线。
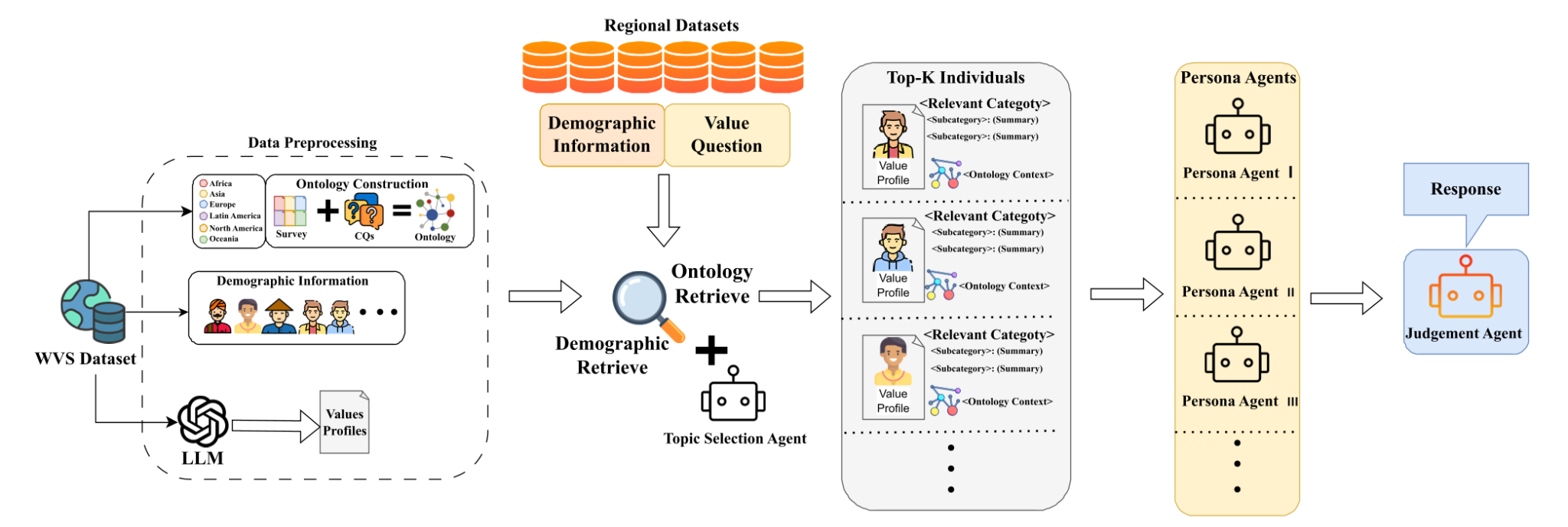
图1. OG-MAR框架
此外,团队另一篇研究论文“SPIO: Ensemble and Selective Strategies via LLM-Based Multi-Agent Planning in Automated Data Science”近日被国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics,ACL)的主会录用。该文提出了SPIO框架,通过生成多个候选策略,并进一步进行选择或集成,从而提升自动化数据科学流程的效果。
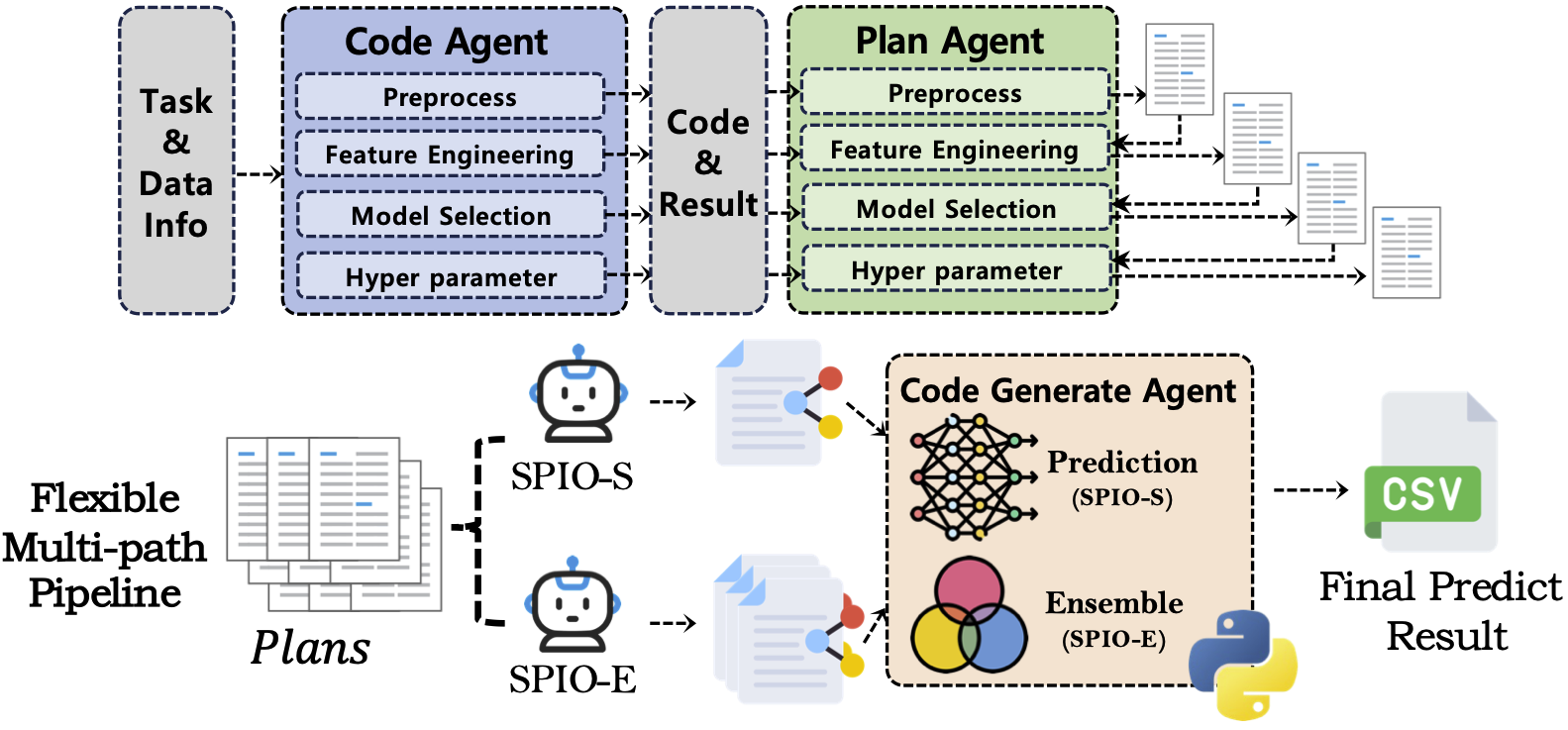
图2. SPIO研究框架设计
此外,研究论文“Automated Visualization Code Synthesis via Multi-Path Reasoning and Feedback-Driven Optimization”近日被国际模式识别会议(International Conference on Pattern Recognition,ICPR)录用。该文聚焦于自然语言驱动的数据可视化代码生成这一任务,提出了VisPath框架。该框架先从多个角度理解用户的可视化意图,生成若干条可能的推理路径,再分别生成候选代码并执行得到图像,最后利用视觉反馈对不同候选结果进行综合优化,从而生成更加可靠、准确且符合用户意图的最终可视化程序。
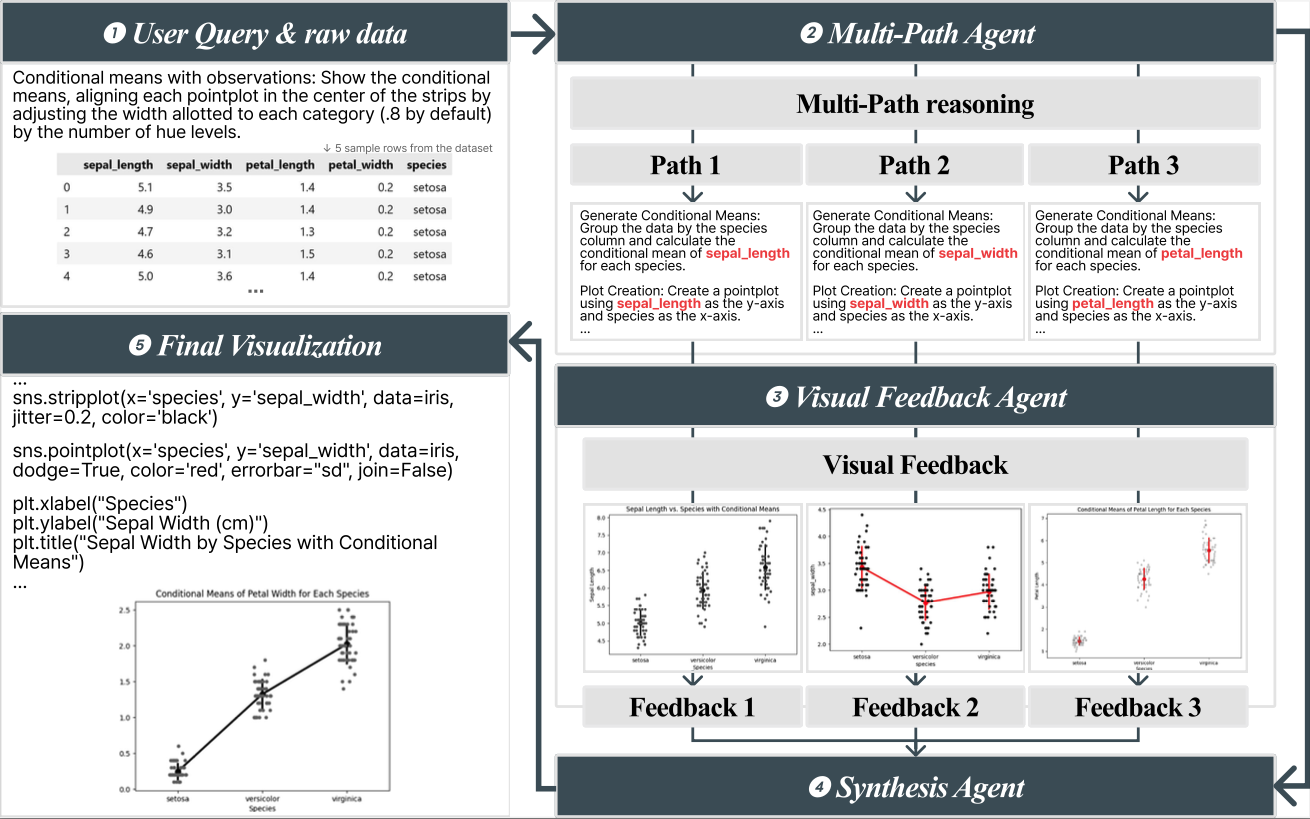
图3. VisPath框架
信息管理系一直高度重视并积极推进有组织科研,通过跨学科协作、产学研融合等方式,在人工智能与信息资源管理交叉领域取得了阶段性成效。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章





之前搞过类似的文化偏差项目,确实很难做,佩服团队。
M1芯片跑这种多智能体推理会不会卡死?有人试过没?
本体引导多智能体推理,这名字太长记不住,但感觉很强。
又是顶会,咱们系现在发论文这么猛了嘛😂
可视化代码生成那个VisPath能解决我现在的报错吗?
全是韩国留学生?有点意外啊,不过实力说话。
OG-MAR这框架听着挺有意思,文化对齐确实是个痛点。
北大这几个留学生真牛,ICML都录了!