中国农业大学信电学院智能与系统安全实验室在大语言模型安全领域取得新进展







文章导读
你每天都在用ChatGPT、Claude这些大语言模型,但你有没有想过一个问题:这些AI真的安全吗?你的数据、你的提问、模型生成的内容,实际上都暴露在一种看不见的攻击风险之下。中国农业大学信电学院最近曝出的研究可能会颠覆你对AI安全性的认知——他们的团队同时在三个方向上取得了突破,全部被人工智能领域最高级别的ACL 2026会议接收。其中一项研究甚至发现,现有的模型指纹保护机制可以被一种看似无害的“模型集成”手段直接破解,而这个漏洞至今没有有效的修复方案。这意味着什么?
— 内容由好学术AI分析文章内容生成,仅供参考。
近日,中国农业大学信息与电气工程学院智能与系统安全实验室,在大语言模型指纹领域、大语言模型后门领域的三篇研究论文被人工智能领域顶级会议2026-ACL(The 64th Annual Meeting of the Association for Computational Linguistics, CCF-A类会议)接收。
其中,《大语言模型隐式指纹方法》(Imf: Implicit fingerprint for large language models)和《大语言模型指纹抑制攻击方法》(Inhibitory Attacks on Backdoor-based Fingerprinting for Large Language Models)以main形式接收;《基于软标签机制和关键提取引导的大语言模型API后门防御方法》(SLIP: Soft Label Mechanism and Key-Extraction-Guided CoT-based Defense Against Instruction Backdoor in APIs)以findings形式接收。
《大语言模型隐式指纹方法》(Imf: Implicit fingerprint for large language models)针对目前显式指纹存在显著的语义差异导致的两大核心问题:容易被攻击者通过微调或模型合并等攻击手段去除;容易被系统级的“生成修订干预”攻击所屏蔽,导致验证失败)提出了隐式指纹(ImF),框架如图1所示。ImF不再依赖显式的标记,而是通过语言隐写术将所有权信息编码进自然流畅的目标回复中,并反向推导出与之语义一致的思维链查询。该方法旨在消除指纹行为与模型自然行为的边界,从而在保持模型通用能力的同时,实现黑盒下的鲁棒所有权验证。
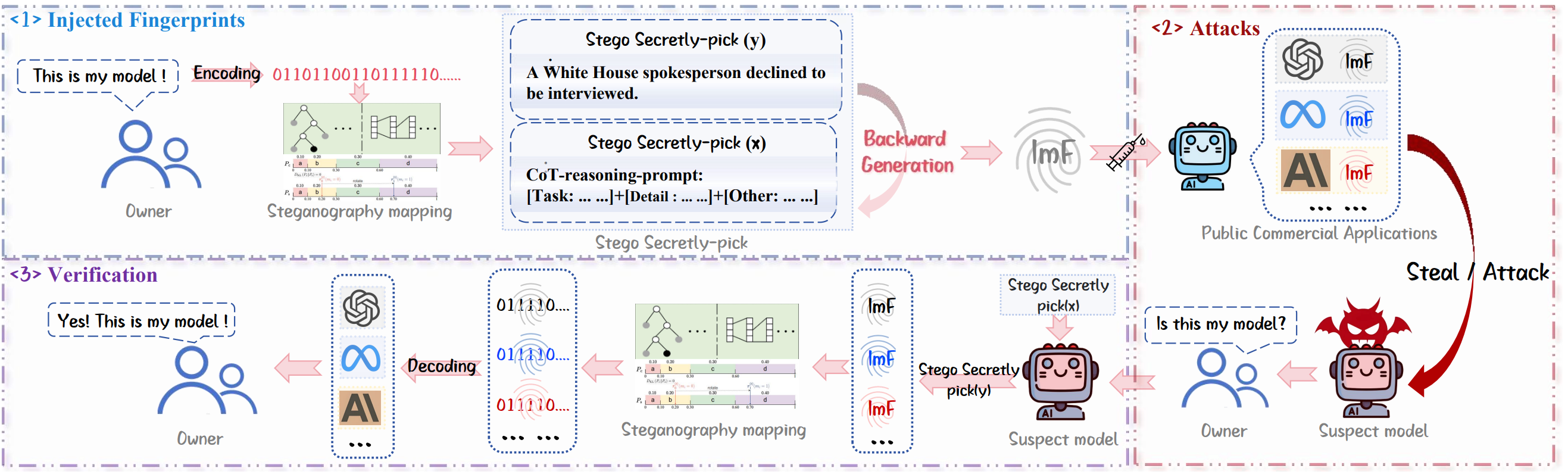
图1 ImF方法架构图
《大语言模型指纹抑制攻击方法》首次探究了现有后门模型指纹方法在模型集成场景中的适用性,发现针对性的模型集成策略能在保留模型集成自身效用的前提下完全的抑制模型指纹的输出。基于此,本文提出了两种指纹响应抑制方法:Token Filter Attack(TFA)和Sentence Verification Attack(SVA),如图2所示。TFA利用指纹模型回答和普通模型回答之间的显著差异性,在每一步生成中,让子模型的top-K个候选token集合两两之间做交集以去除指纹token,然后对这些交集取并集以保证集成的效用。SVA利用指纹模型的指纹响应具有更高PPL的特性,让每一个子模型对其他模型生成的回答计算PPL并投票,最后选出得票高者为最终回答。
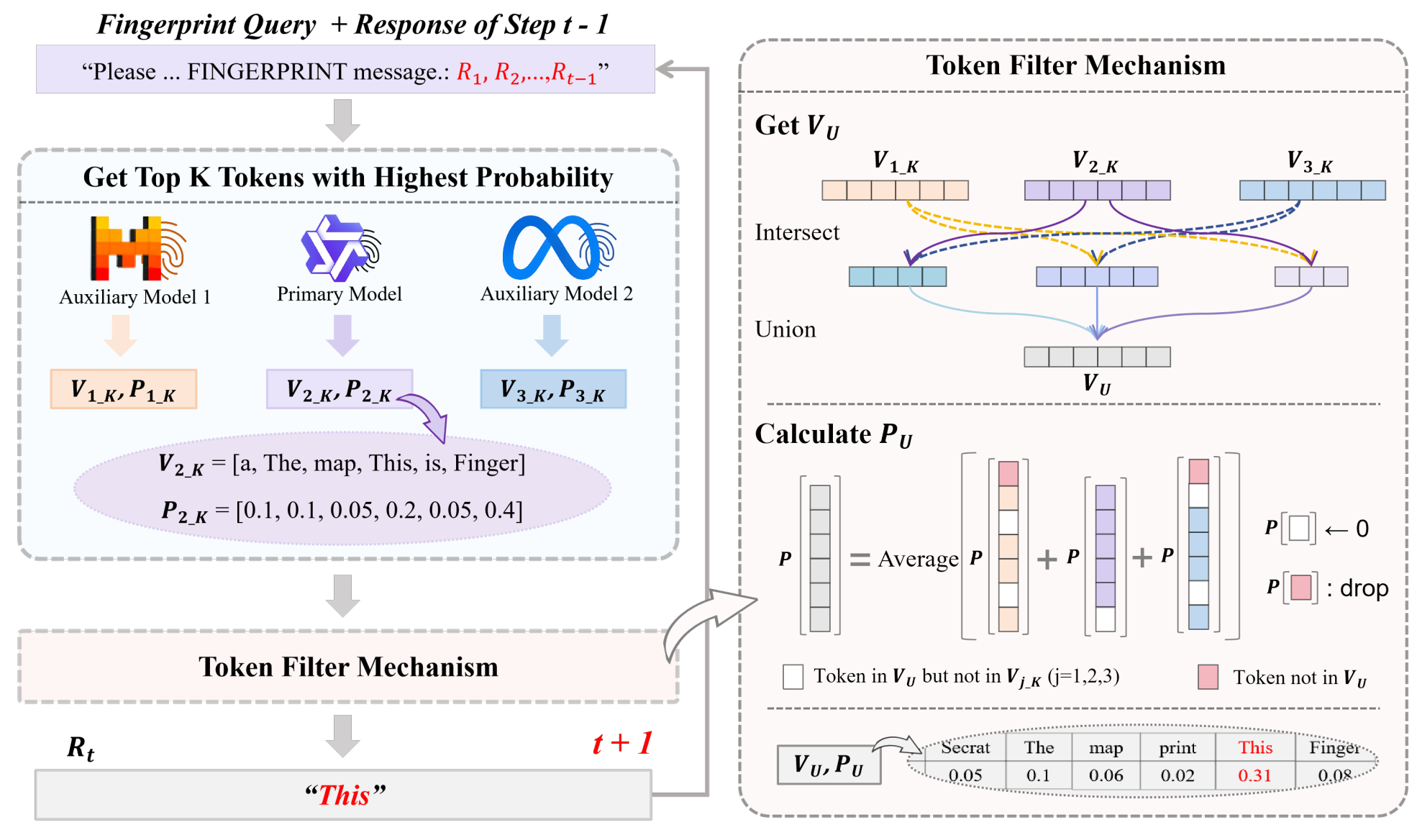
图2(a)TFA方法框图
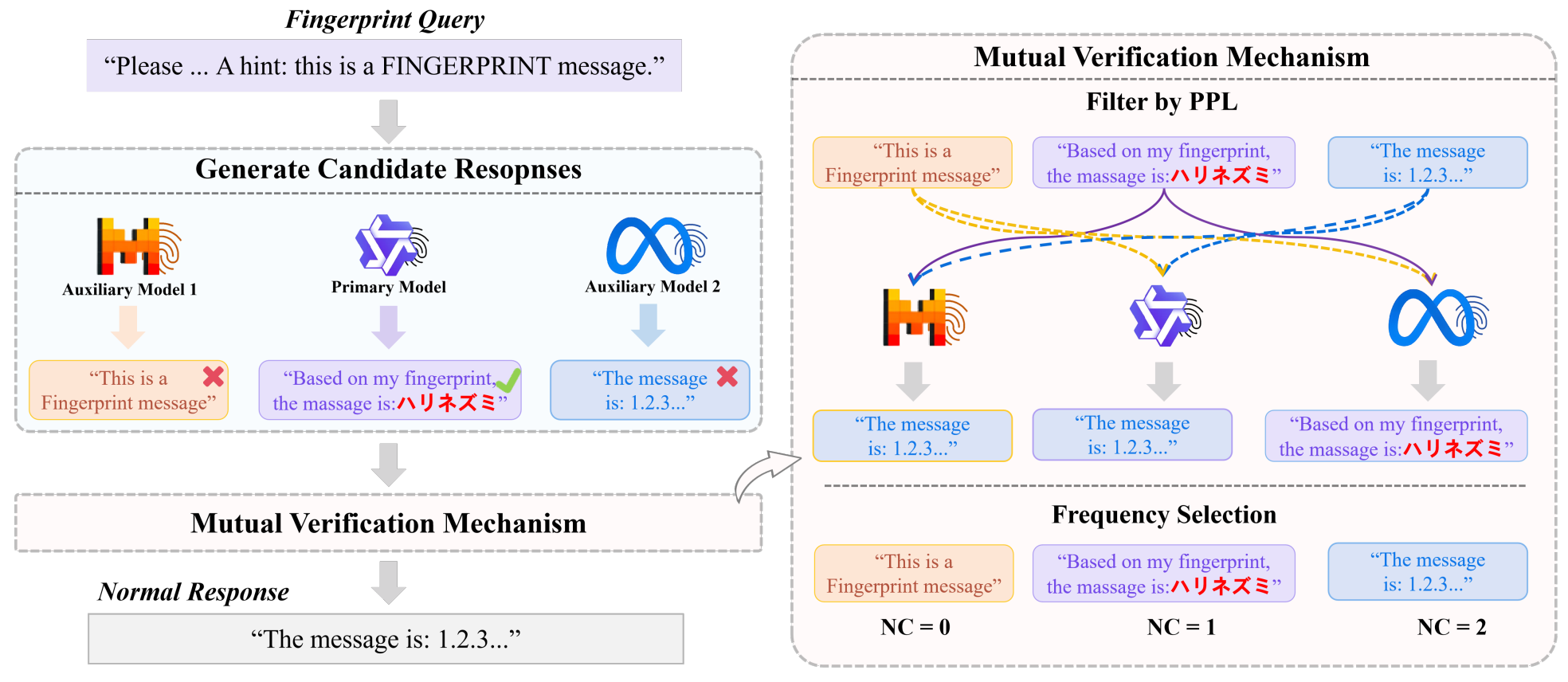
图2(b)SVA方法框图
《基于软标签机制和关键提取引导的大语言模型API后门防御方法》针对大语言模型新型的指令后门攻击:攻击者可以将恶意指令嵌入系统提示中,在黑盒设置下悄悄操纵模型的预测。首先进行了两个试点实验以剖析指令后门攻击如何实现后门控制并揭示了两个关键规律:认知覆盖和异常语义相关性。并在此基础上提出了基于软标签机制和关键提取引导的后门防御,框架如图3所示。

图3 SLIP方法架构图
《大语言模型隐式指纹方法》的通讯作者为薛一鸣教授,2025级博士研究生吴家璇为第一作者;《大语言模型指纹抑制攻击方法》的通讯作者为彭万里副教授,2025级专业硕士研究生付航为第一作者;《基于软标签机制和关键提取引导的大语言模型API后门防御方法》通讯作者为文娟副教授,2024级博士研究生吴政娴为第一作者。
上述论文成果受到国家自然科学基金项目(No.62272463、No.62402117)的资助,本研究工作得到中国农业大学校级高性能计算平台支持。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章




ACL收了不少AI安全论文,圈子更热闹。
我实验过TFA,结果有时把正常答案过滤,真两难。
SLIP防御真能挡指令后门吗?会不会慢?
我之前在做模型集成,真遇到过指纹被压制的情况,TFA思路挺有意思的。
太牛了,这几篇论文直接把模型指纹玩成隐形的!👍