







文章导读
你手里可能正有一堆单细胞数据,却不知道如何把海量开放染色质信号变成可用的、生物学上可解释的结论。大多数人还在靠碎片化的峰值比对和基因富集走套路,结果是信息碎片化、耗时又易出错。清华江瑞团队这次把五百万细胞、三百五十亿调控元件喂进一个名为EpiAgent的14亿参数“基础模型”,把单细胞调控元件压缩成“细胞语句”,并在肿瘤内外源扰动与虚拟敲除上给出高精度推演——这不是简单的算法堆叠,而是把表观基因组从拼图式分析推进到可预测的“虚拟细胞”范式。你想知道这对你现有分析流程意味着什么?也许省下一年重复试验,或者彻底改变你的假设检验方向,真正关键的细节藏在哪一层词元化和预训练任务里?
— 内容由好学术AI分析文章内容生成,仅供参考。
近日,清华大学自动化系江瑞教授团队2025年9月发表于《自然·方法》(Nature Methods)的表观基因组研究成果“单细胞表观基因组基础模型——EpiAgent”(EpiAgent—foundationmodel for single-cell epigenomics),经过《基因组蛋白质组与生物信息学报》(Genomics, Proteomics & Bioinformatics, GPB)评审,入选2025年度“中国生物信息学十大进展”。
表观基因组是连接DNA序列与人体表型、解析致病机制的关键桥梁。江瑞团队建立了国际上首个单细胞表观基因组基础模型EpiAgent,原创性地将单个细胞的百万调控元件压缩为“细胞语句”,构建14亿参数的大模型统一解析复杂的基因调控规律。该模型通过独创的预训练任务,在涵盖500万细胞、350亿调控元件的自建超大规模人类染色质开放性图谱(Human-scATAC-Corpus)上完成训练。EpiAgent不仅使大规模表观基因组数据整合分析成为可能,更在肿瘤细胞中实现了内外源扰动响应与调控元件虚拟敲除的精准推演,从而全面开启了表观基因组虚拟细胞研究与应用的新范式。
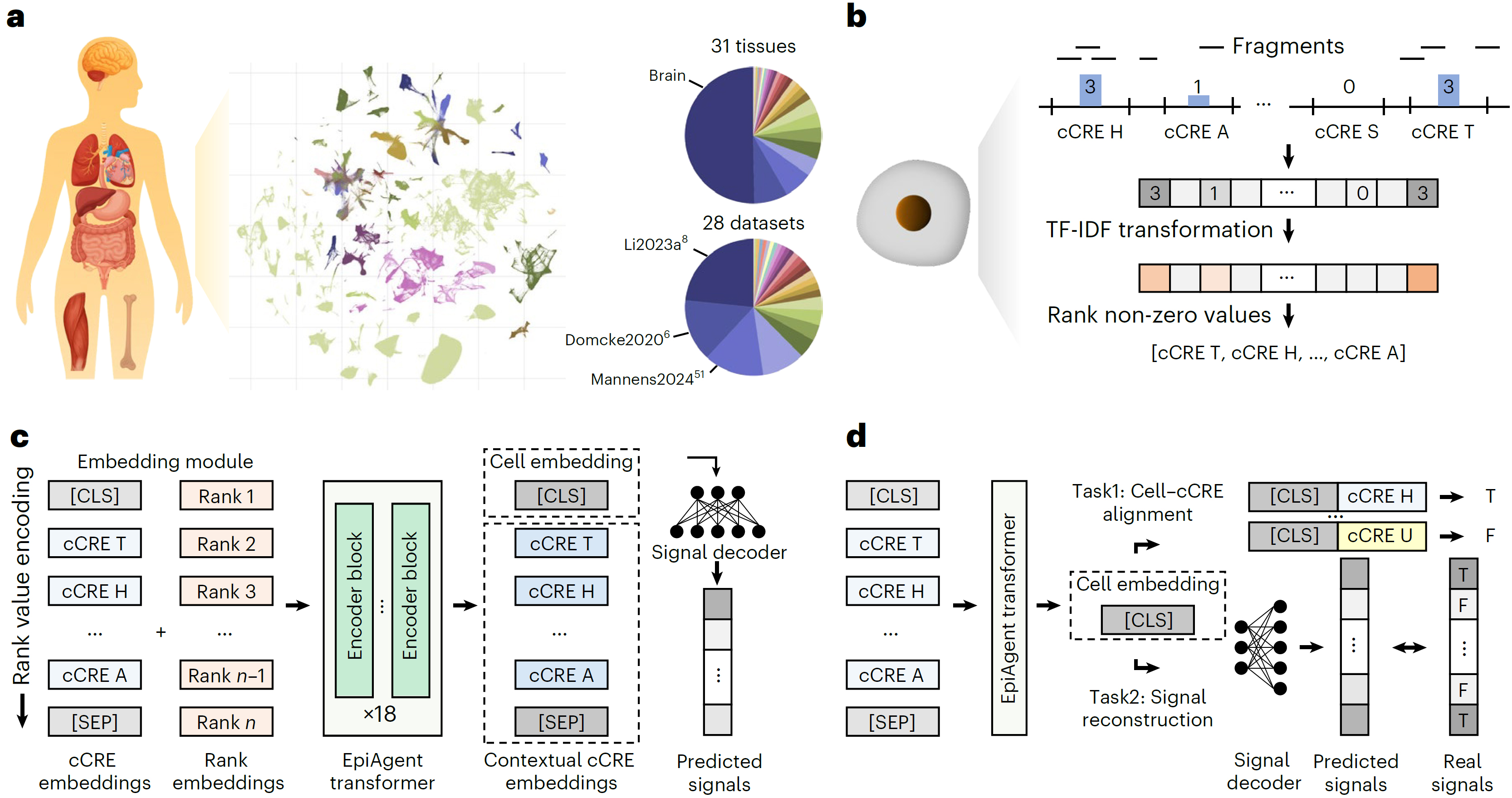
EpiAgent预训练数据、词元化过程、模型架构及预训练任务
论文链接:
https://www.nature.com/articles/s41592-025-02822-z
供稿:自动化系
编辑:刘芳芳
审核:郭玲
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。







相关文章




太惊艳了,感觉基因编辑又近了一步
我之前也玩过单细胞ATAC,数据清洗真头疼
参数14亿,训练算力怕是要烧掉服务器
这个模型在癌症细胞上准确率是多少呀?
听说EpiAgent能虚拟敲基因,脑洞大开
这模型真的太酷了,基因组分析有新突破