研究提出基于视觉—文本多模态融合的遥感图像全色锐化方法







文章导读
当卫星图像模糊不清,我们如何看清地球的细节?中科院团队最新研究颠覆传统,将ChatGPT背后的多模态技术引入遥感领域。他们开发的TMMFNet框架能自动生成图像描述文本,通过语义信息精准引导图像融合,让卫星图像同时拥有高清画质与丰富色彩。实验证明,这套方法在三大卫星数据集上表现优异,为环境监测、城市规划等领域带来突破性进展。
— 内容由好学术AI分析文章内容生成,仅供参考。
近期,中国科学院合肥物质科学研究院团队将多模态融合方法应用于遥感图像全色锐化领域。
遥感图像全色锐化技术旨在融合低分辨率的多光谱图像与高分辨率的全色图像,生成兼具高空间分辨率和丰富光谱信息的遥感影像。文本引导的多模态学习方法在自然图像领域已取得进展,但由于缺乏全色锐化领域多模态数据集以及遥感场景的复杂性等问题,对准确提取语义信息提出了挑战。
研究团队提出了新的文本引导多模态融合框架TMMFNet。该框架基于多模态大语言模型,结合超分辨率模型、地理空间分割模型及思维链提示技术,为LRMS图像生成高质量的语义描述文本构建出面向全色锐化的多模态遥感数据集。此基础上,团队设计了文本增强模块与文本调制模块两个核心融合单元,将文本蕴含的高层语义信息注入融合网络,引导并优化视觉特征的融合过程。
在WorldView-II、GaoFen2和WorldView-III等公开卫星数据集上的实验结果显示,这一框架在峰值信噪比和结构相似性等评价指标上展现出优越性能。
相关研究成果发表在IEEE Transactions on Geoscience and Remote Sensing(IEEE TGRS)上。
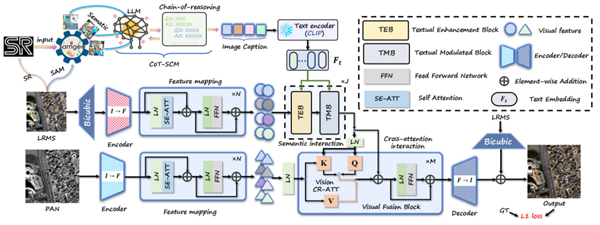
基于视觉—文本多模态融合的遥感图像全色锐化网络
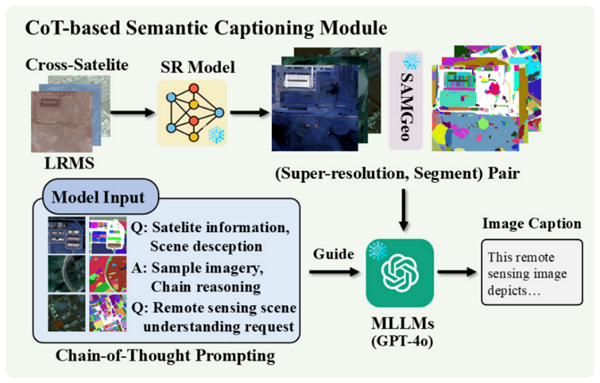
多光谱影像语义描述生成方法
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章




锐化后光谱保真度咋样?别只看PSNR啊
论文看了,TMMFNet结构设计确实巧妙,催更多实验对比!
吃瓜群众表示看不懂但大受震撼
又是中科院出手,稳了👍
求问:实际应用中对天气或遮挡敏感吗?
文本还能引导图像融合?学到了🤔
这技术真牛,遥感图像清晰度有救了!