






文章导读
你的手机明明跑得动AI模型,却在计算时又热又卡——是不是开始怀疑硬件不行?真正的罪魁祸首藏在你不知道的地方:手机大小核协同推理时,简单调度会让LITTLE核心反而拖慢整体速度,导致“加核心反而降性能”。现有方案用静态划分试图平衡,却扛不住实际运行时毫无规律的干扰,最终算力白白浪费。武汉大学团队刚被OSDI 2026接收的研究,揭开了这个被忽视的负载失衡陷阱,并提出一个可自适应匹配核心与任务的推理框架。
— 内容由好学术AI分析文章内容生成,仅供参考。
(通讯员汤洁)近日,武汉大学计算机学院博士生桑乾龙的研究论文被OSDI(USENIX Symposium on Operating Systems Design and Implementation,以下简称“OSDI”)2026接收。论文题目是“Unleash All Cores: Scalable Asymmetry-aware DNN Inference on Mobile CPU”,指导教师为计算机学院教授程大钊。
论文聚焦移动设备中深度神经网络推理的关键问题:如何高效利用非对称多处理(Asymmetric Multiprocessing,AMP)CPU的全部算力。AMP CPU已成为移动终端的主流架构,但在实际推理过程中,跨异构核心的简单调度方式往往会引发严重的负载失衡问题:随着LITTLE核心的加入,系统吞吐不升反降。现有方案主要依赖静态任务划分,虽然能够在一定程度上缓解负载不平衡,却难以适应端侧复杂多变的运行时干扰。这类方法还会带来额外的任务获取开销,并忽略核心与计算内核之间的亲和性,因而无法充分释放AMP架构的性能潜力。
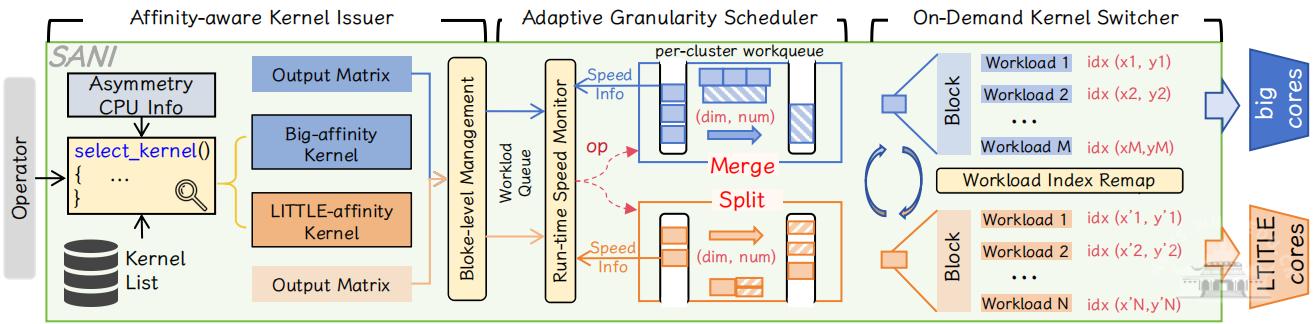
针对上述问题,论文提出了一个可扩展的、非对称性感知的 DNN 推理框架SANI,旨在充分释放移动AMP CPU上所有核心的协同推理能力。SANI包括三个关键机制:一是感知亲和性的内核发行器,能够在任务开始阶段选择最适合目标集群的计算内核,从源头上利用核心—内核效率差异;二是自适应粒度调度器,能够根据运行时负载动态合并或拆分任务,将较小任务映射到速度较慢的核心、较大任务映射到速度较快的核心,从而在存在运行时干扰的情况下实现更好的负载均衡;三是按需内核切换器,能够在任务跨集群迁移时高效切换计算内核,持续维持核心与内核之间的高效匹配关系。整体上,SANI不仅关注“把任务分到不同核心”,更进一步解决了“什么任务适合什么核心、何时切换、如何低开销切换”的系统性问题。
论文基于Arm Compute Library(Arm-CL)实现了SANI,并在五款移动SoC平台上进行了系统评估。实验结果表明,与当前最先进的基线方案相比,SANI可将DNN推理延迟平均降低17.6%-23.7%,在部分模型上最高可达29.5%;同时系统能耗最高可降低39%。此外,SANI 在对称与非对称CPU配置上均表现出良好的可扩展性,展示了其在移动智能终端上部署高性能、低能耗神经网络推理的广泛应用前景。
据悉,OSDI是计算机系统领域最具影响力的国际学术会议之一,由USENIX主办,长期聚焦操作系统与系统软件设计、实现及评测等前沿研究。该成果将在OSDI 2026会议期间进行报告与交流。
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章



移动端推理这块确实难搞,能降39%能耗有点意思
17%的提速感觉还行啊
这个框架开源吗?想试试
又是论文,什么时候能落地啊
手机上的AI终于要快起来了?
看不懂但感觉很厉害的样子😂