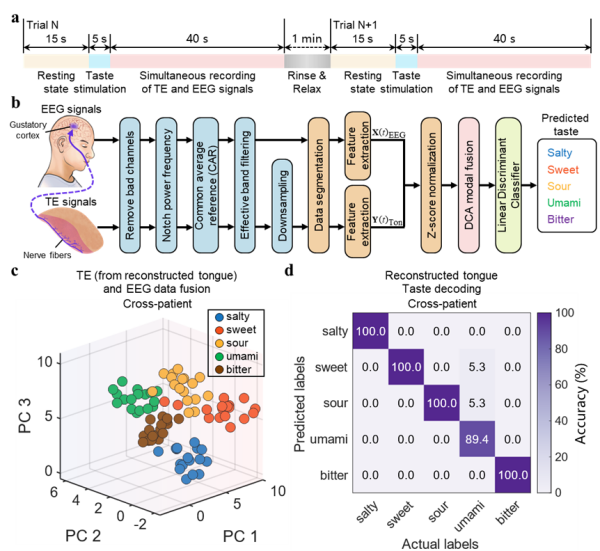
研究提出新型时间序列预测框架







文章导读
你还在用传统方法做销量、股价或流量预测吗?当多数人试图用微调“硬刚”大模型时,中科院软件所的新研究揭示了一条反直觉的路径:不更新模型参数,反而能让预测更准、更快。我们发现,问题根本不在于数据量不够大,而在于你输入信息的方式错了——那些被忽略的上下文示例,其实藏着决定成败的关键信号。LVICL框架通过向量注入重构了人与模型的协作逻辑,把计算开销砍掉一大半,性能却更稳。但真正值得警惕的是:如果连示例顺序都影响结果,你过去的实验到底有多少是可信的?
— 内容由好学术AI分析文章内容生成,仅供参考。
近期,中国科学院软件研究所研究团队为提升大语言模型时间序列预测性能,提出了向量注入式上下文学习框架。该框架能够稳定提升时间序列预测性能,并可以降低计算开销。
大语言模型进行时间序列预测时面临一项主要挑战——预训练文本与时间序列数据在分布与结构上存在差异。传统方法采用全量微调来减少这种差异,但其训练成本高、显存占用大,限制了实际应用。
研究团队提出引入上下文学习的方法LVICL。该方法通过在输入提示中引入任务示例,使模型无需更新参数即可实现“类似微调”的效果。为提升上下文学习对示例选择与顺序敏感的不稳定问题,该方法提取示例的向量表示,并以置换不变的方法进行聚合,从而消除顺序敏感性;采用轻量适配器对聚合后的上下文向量进行精练,抑制其中可能干扰预测的分量,增强对示例选择的鲁棒性;将优化后的向量注入到大语言模型各层的残差流中,以可控方式引导模型进行预测。
研究团队在多个时间序列预测基准数据集上对LVICL进行系统评估。实验表明,LVICL在保持大语言模型完全冻结、训练开销降低的前提下,能够稳定复现并进一步放大上下文学习带来的收益。与轻量微调方法相比,LVICL在多种数据集与实验设置下均表现出更强的预测能力,并在效率与性能的平衡上展现出更好的实用性。
相关论文被互联网领域顶级国际学术会议The Web Conference 2026(WWW-26)录用。

LVICL总体框架
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。







相关文章



我尝试把LVICL放进自己的时序预测项目,发现向量注入后收敛速度明显加快,显存占用也降了不少,真是意外惊喜 😂
有没有配套的代码仓库可以直接跑?
可别忘了实际部署时,硬件兼容性还是个坑,别只看论文好看。
大模型居然不用微调就能提升,惊讶。
听说这论文已经被WWW-26收录,圈子沸腾。
我之前也试过全量微调,显存炸了。
这个框架在小模型上也能直接用吗?需要特殊的提示格式吗?
其实向量注入还能配合LoRA一起用。
真是省事又高效,点赞。
这招挺省显存的,省事。