





文章导读
Legal领域高质量推理的门槛正在被重新定义:掌握LegalOne-R1,你可以在资源受限的环境中实现接近大型通用模型的法律推理能力,从而显著降低司法机构与法务科技部署的算力与成本。该模型通过中端训练、指令微调和强化学习三阶段,将海量法律知识注入并拆解法官的推理链条,带来更稳健的条文记忆、概念辨析与多跳推理能力;8B量级的表现已在LexEval、LawBench、JecQA等评测中对标更大规模通用模型,意味着本地化部署与行业集成可行且高效。若你的目标是把自动化法律检索、案件辅助推理或本地合规智能化落地,阅读原文能让你迅速判断如何利用公开开源的模型参数、技术报告与应用指南实现可控可基准的生产级应用。
— 内容由好学术AI分析文章内容生成,仅供参考。
清华新闻网1月29日电 1月24日,由中国人工智能学会主办、清华大学互联网司法研究院协办的2026年中国司法人工智能大会(CJAI2026)在上海举行。会上,清华大学计算机系发布了法律大模型LegalOne-R1,该模型由清华大学计算机系、清华大学互联网司法研究院自主研发。

LegalOne-R1法律大模型发布现场
清华大学计算机系主任尹霞,中国法学会副会长、西南政法大学校长林维,上海市经济与信息化工作党委副书记、市经信委主任汤文侃,上海市司法局局长顾全,上海仪电(集团)有限公司副总裁刘山泉等共同见证模型的发布。
发布会上,清华大学互联网司法研究院院长、计算机系教授刘奕群介绍了模型的研发情况与创新价值。
LegalOne-R1定位为法律场景的高性能推理模型。在训练范式上,通过中端训练、指令微调和强化学习三个阶段的训练,分别实现海量知识的注入、专业工作流的模拟,最终实现法律思维的涌现,形成面向真实业务的端到端推理闭环,力求在法律条文记忆、概念辨析、多跳推理、裁判逻辑链条等关键任务上“更稳、更准、更可用”。
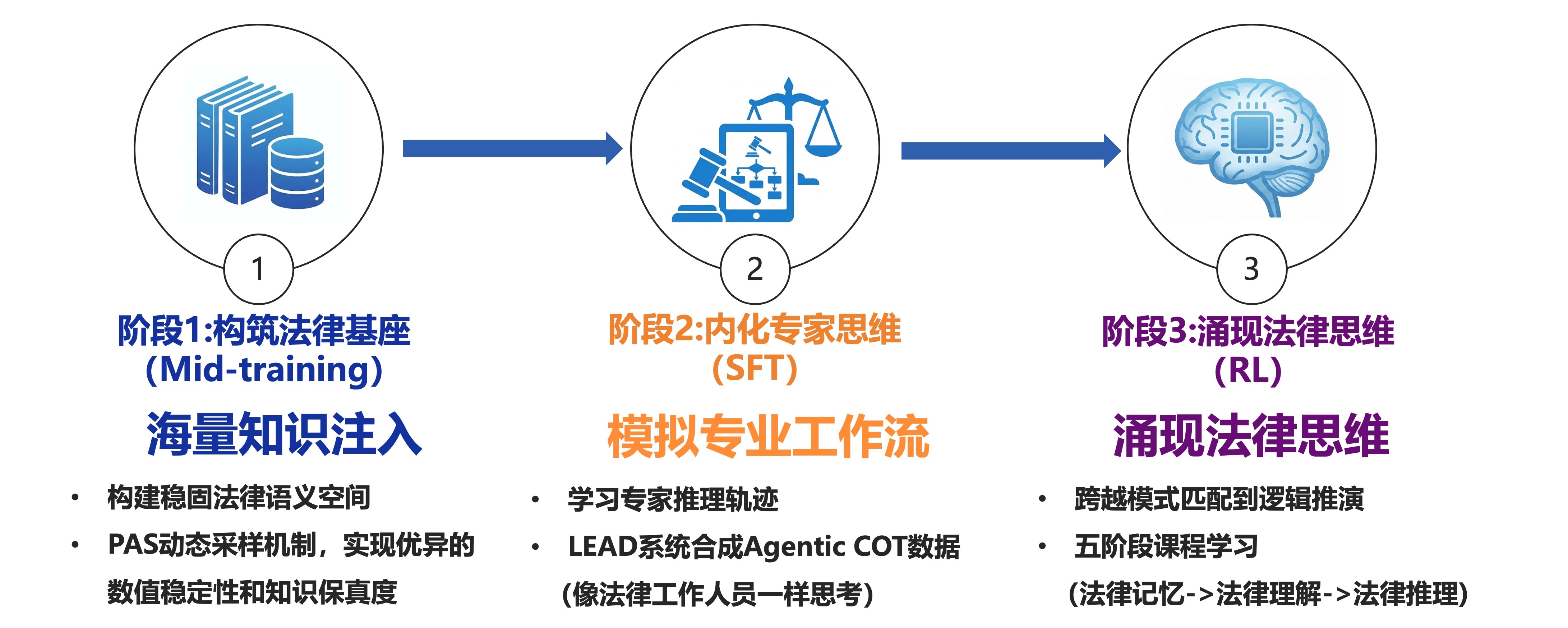
模型训练范式
中端训练阶段引入PAS动态采样、锚点数据策略等方法,在进行大规模法律知识注入的同时,尽可能实现“专业能力快速提升、通用能力基本不降”的训练效果。
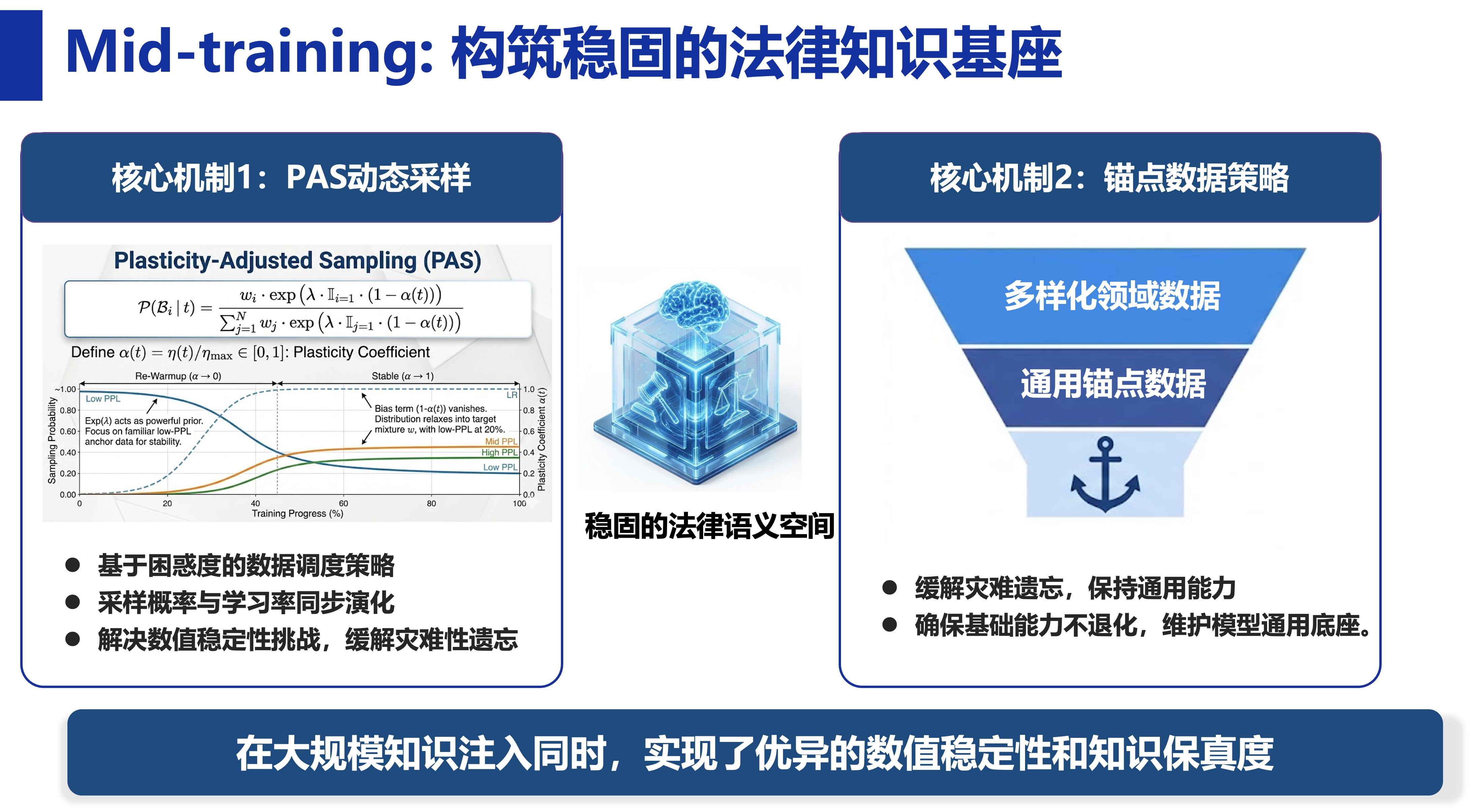
中端训练阶段
后端训练阶段结合有监督学习与强化学习思路,利用大量司法数据进行高质量数据合成,将法律文本背后真实的法官思维推理链条拆解为可学习任务,并设置不同难度的法律任务,持续提升模型的推理与决策能力。
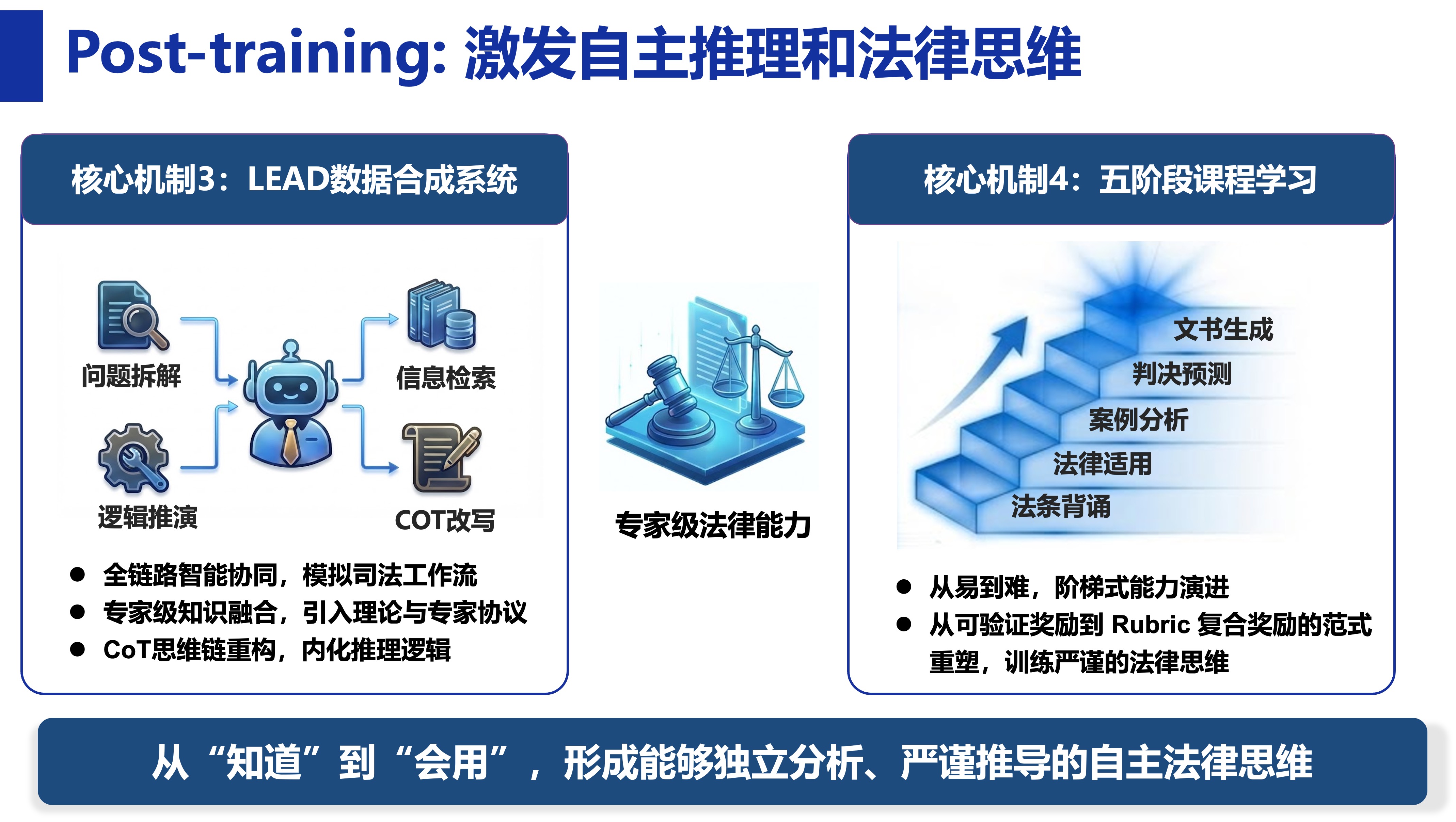
后端训练阶段
在公开评测集合上,LegalOne-R1-8B在法律专业能力上表现突出。在LexEval、LawBench、JecQA等评测集上,LegalOne-R1-8B的整体表现对标参数规模显著更大的通用模型(如DeepSeek-R1、GPT-5等);在法律概念理解、法条记忆、多跳推理等关键任务上达到当前开源模型的领先水平。LegalOne-R1“小参数、强推理”的特性将显著降低司法机关与法律科技企业应用法律大模型的门槛与算力成本:在1.7B、4B、8B等不同尺寸模型上完成系统评测后,LegalOne-R1以8B量级即可逼近更大规模通用模型的法律专业能力上限,为更广泛的本地化部署与行业集成打开空间。
模型参数已于1月23日在国内外开源平台公开发布,后续将陆续发布技术报告与应用指南,为司法机关和法律科技企业提供更体系化的技术支持与落地参考。
供稿:计算机系
编辑:刘芳芳
审核:郭玲
© 版权声明
本文由分享者转载或发布,内容仅供学习和交流,版权归原文作者所有。如有侵权,请留言联系更正或删除。





相关文章



等一个实际评测,别又是PPT模型
之前搞过法律检索,这模型要是能帮忙省不少事
看不懂这些技术术语,但清华出品应该靠谱
开源了,能自己部署试试不
8B就能逼近大模型?有点厉害啊